Kafka Confluent Cloud is a fully managed event streaming platform powered by Apache Kafka.
You can use Hevo Pipelines to replicate data from your Kafka Confluent Cloud account to the Destination system.
Prerequisites
-
An active Confluent Cloud account from which data is to be ingested exists.
-
One or more bootstrap servers are available in Kafka Confluent Cloud.
-
The API key and secret are available in Kafka Confluent Cloud.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtain the Bootstrap Server Information
Perform the following steps to retrieve the Bootstrap server:
-
Log in to your Kafka Confluent Cloud account.
-
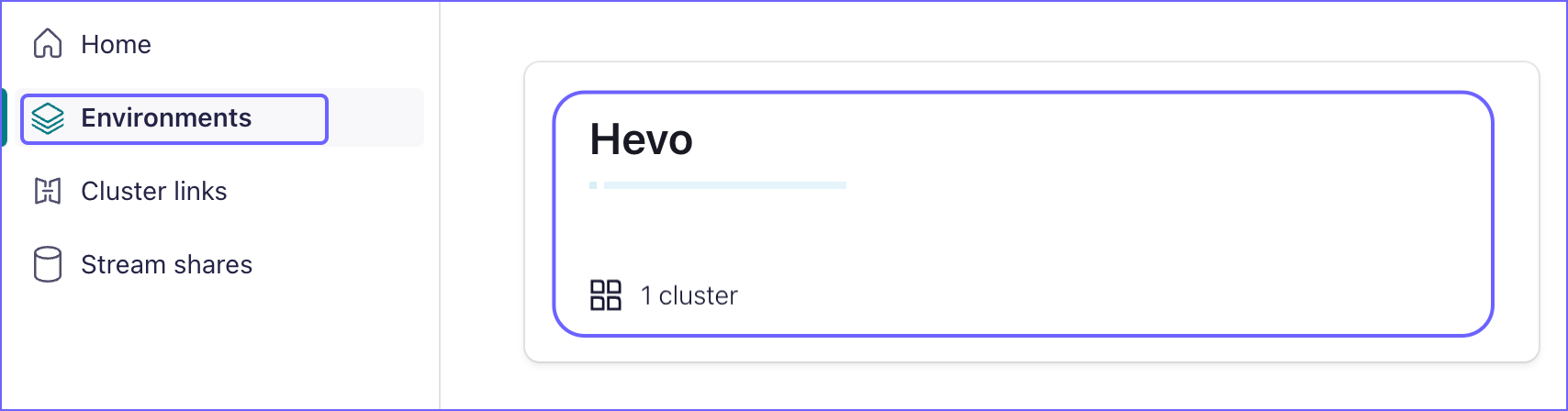
In the left navigation pane, click Environments and then click <Environment name>.
-
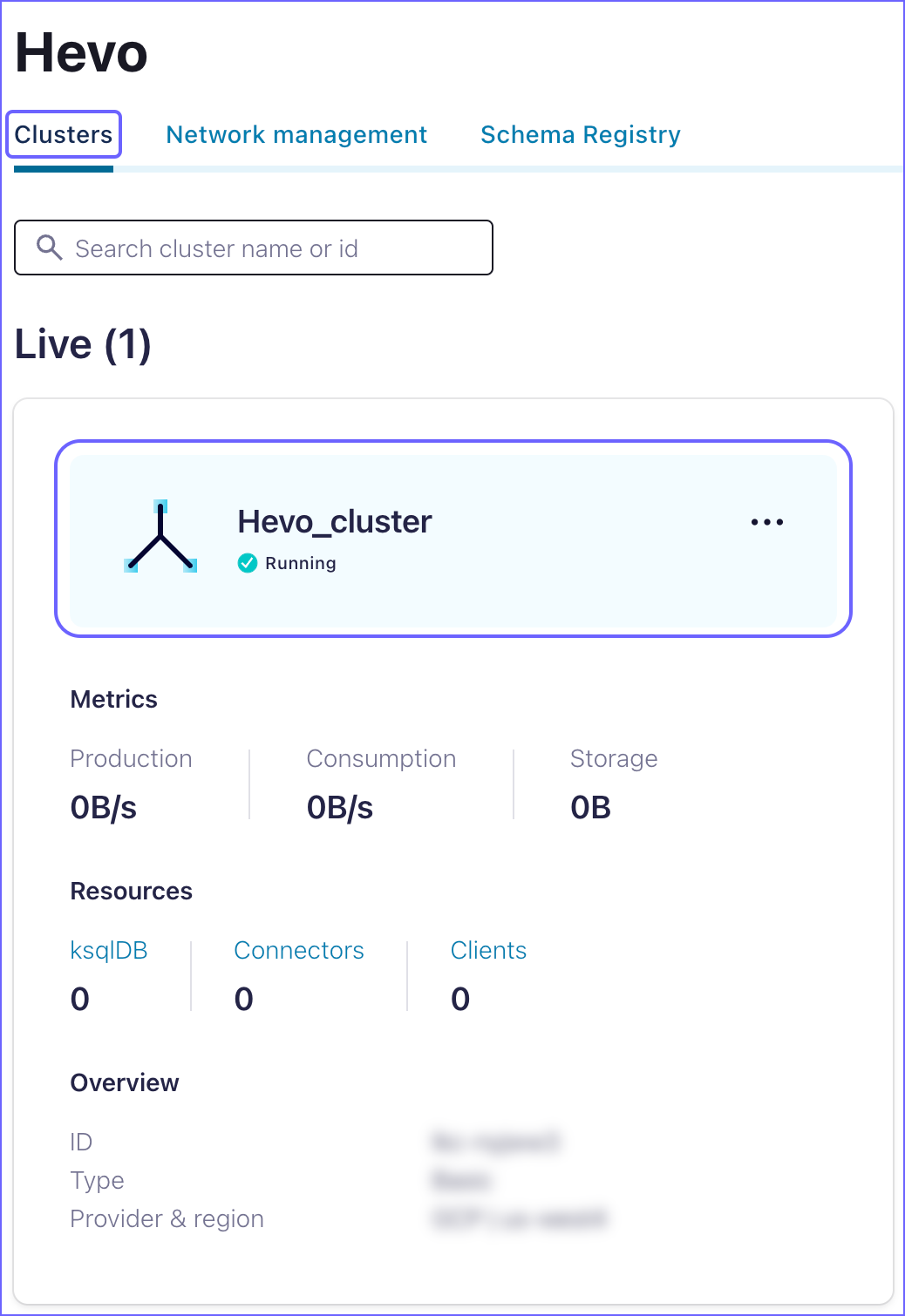
On the <Environment name> page, select the Clusters tab and click <Cluster name>.
-
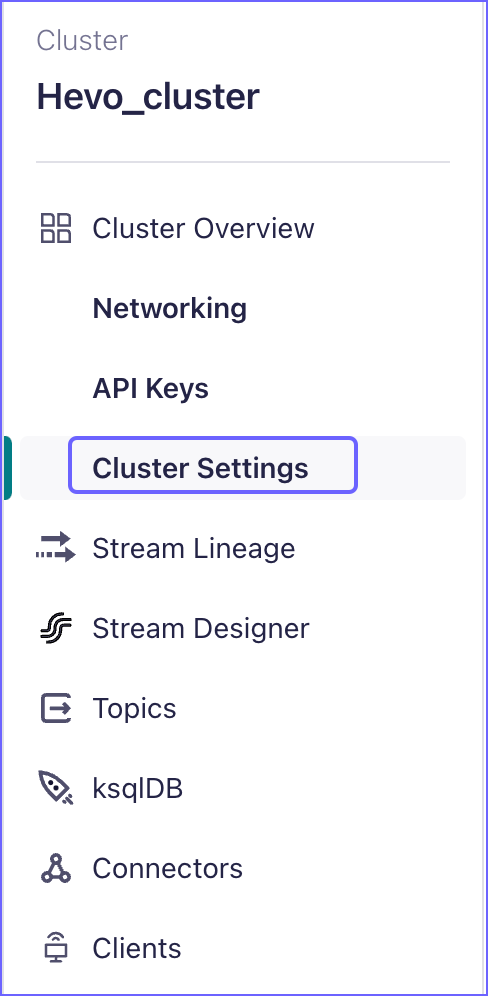
In the left navigation pane, under Cluster Overview, click Cluster Settings.
-
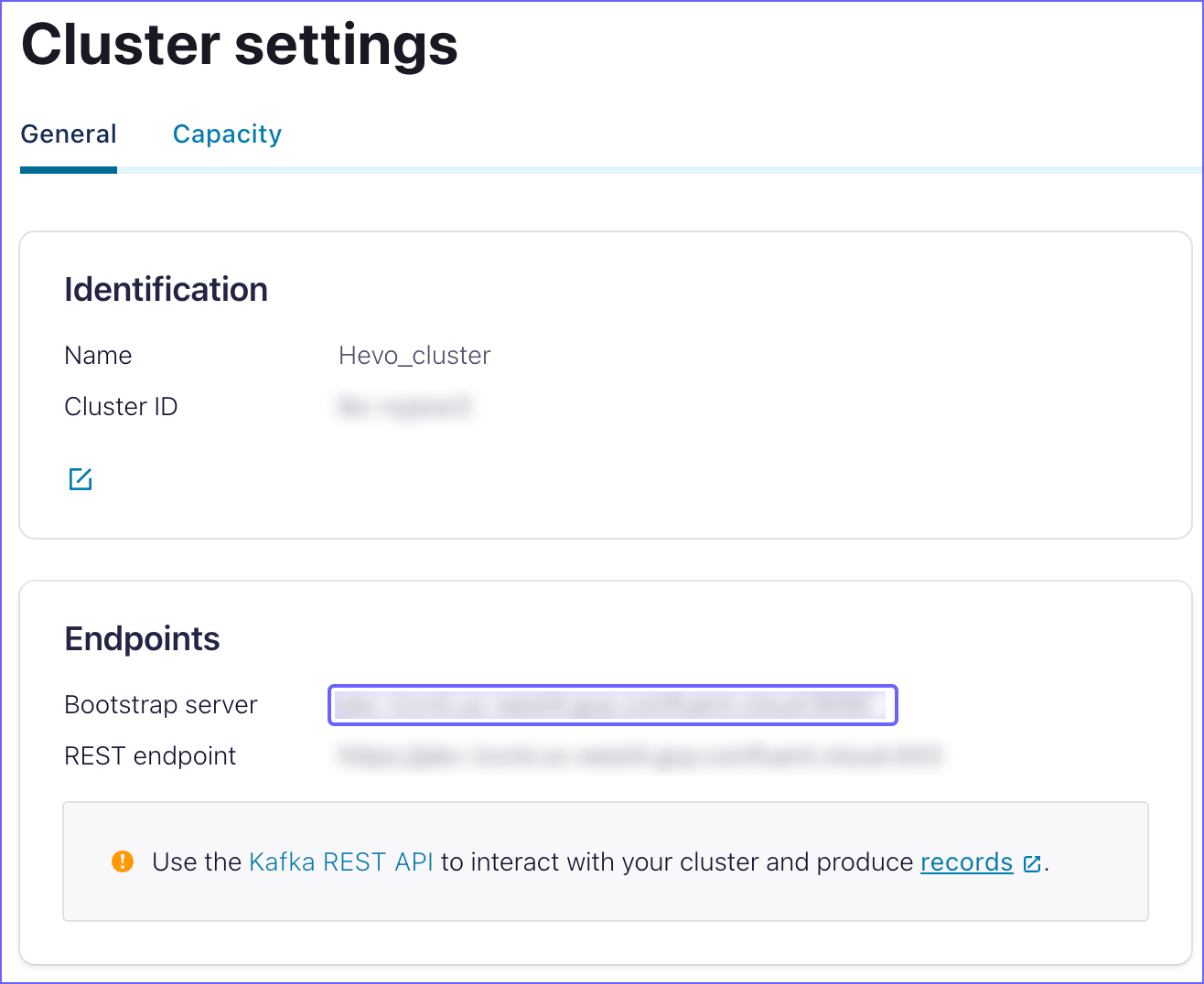
On the Cluster settings page, copy the Bootstrap server endpoint and save it securely like any other password. Use this endpoint while configuring your Hevo Pipeline.
Create the API Key and Secret
Perform the following steps to create the API credentials (API key and secret):
-
Follow steps 1-3 from the above section.
-
In the left navigation pane, under Cluster Overview, click API Keys.
-
On the API keys page, click Create key.

-
On the Create key page, do the following:
-
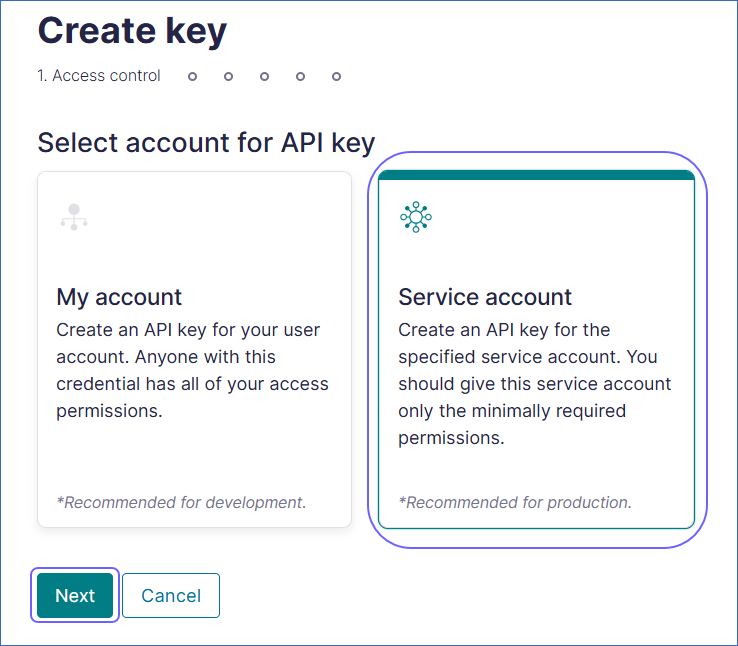
In the Access control tab, select Service account and click Next.
-
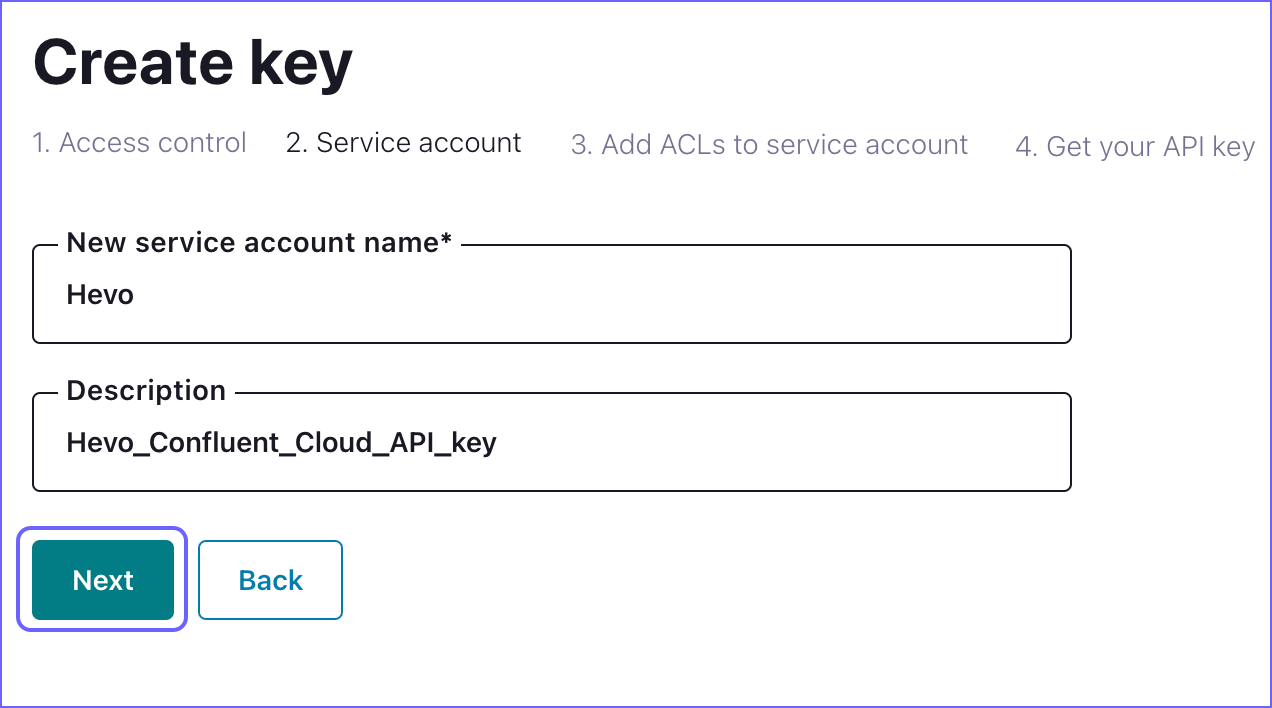
In the Service account tab, specify the following to create a service account and click Next.
Note: ACLs are required to assign permissions for each category of the API key.
-
New service account name: A unique name for your service account.
-
Description: A brief description of your service account.
-
-
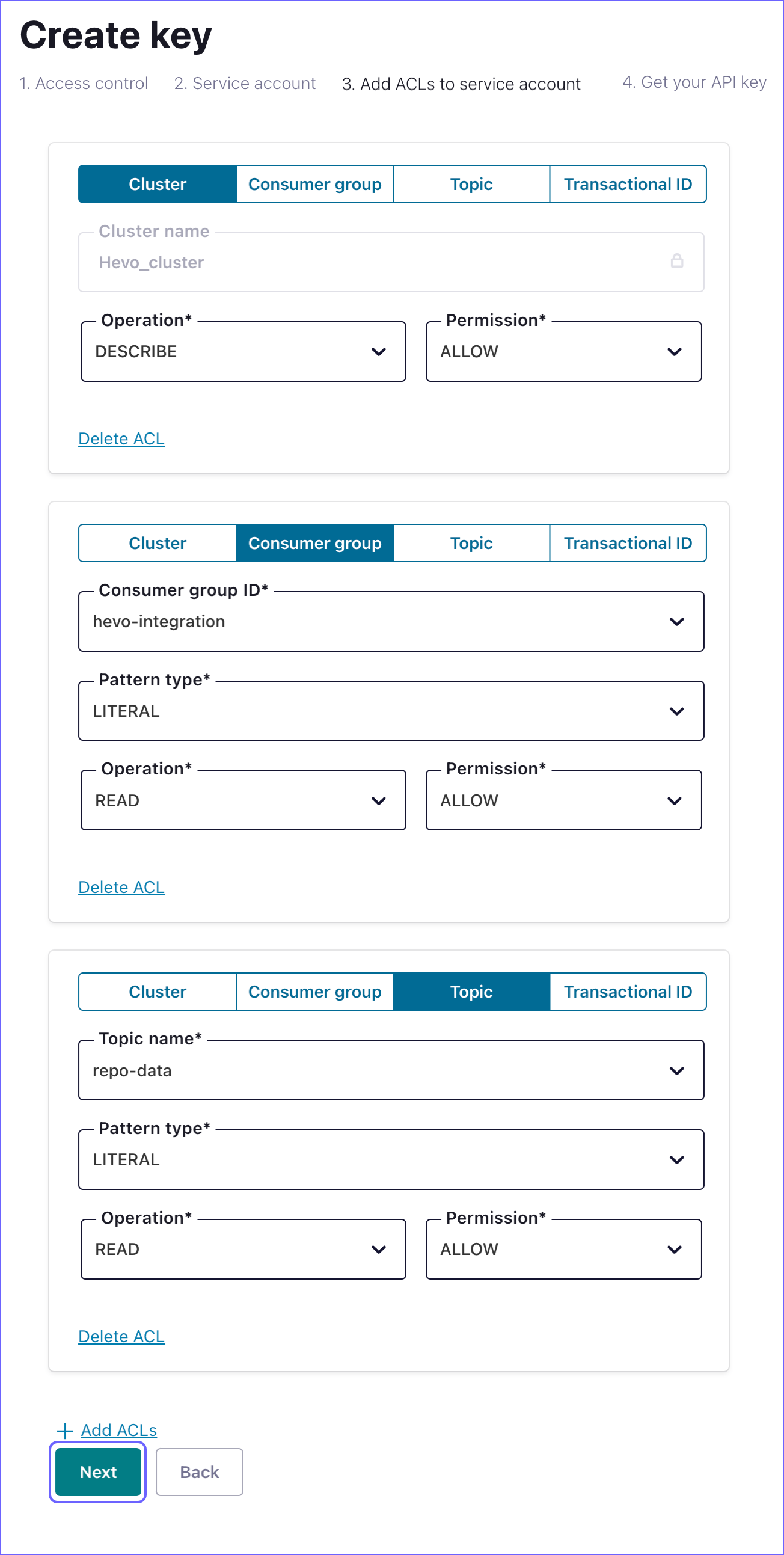
In the Add ACLs to service account tab, specify the Cluster, Consumer group, and Topic ACLs from the table below the image :
Note: You need to click + Add ACLs to define a new ACL.
-
Cluster API
ACL Category Operation Permission Cluster DESCRIBE ALLOW -
Consumer Group ACLs
ACL Category Consumer Group ID Pattern Type Operation Permission Consumer Group hevo-integration PREFIXED DESCRIBE ALLOW Consumer Group hevo-integration PREFIXED READ ALLOW -
Topic ACLs
ACL Category Topic Name Pattern Type Operation Permission Topic The topic for which you grant permission to Hevo. By default, all topics can be accessed. LITERAL or PREFIXED. If the Topic Name specified is *, select LITERAL. READ ALLOW Topic The topic for which you grant permission to Hevo. By default, all topics can be accessed. LITERAL or PREFIXED. If the Topic Name specified is *, select LITERAL. DESCRIBE_CONFIGS ALLOW
-
-
Click Next.
-
In the Get your API key section, click the Copy icon corresponding to the Key and Secret to copy them, and save them securely like any other password.
Note: Once you exit this screen, you cannot see the same API key and secret.
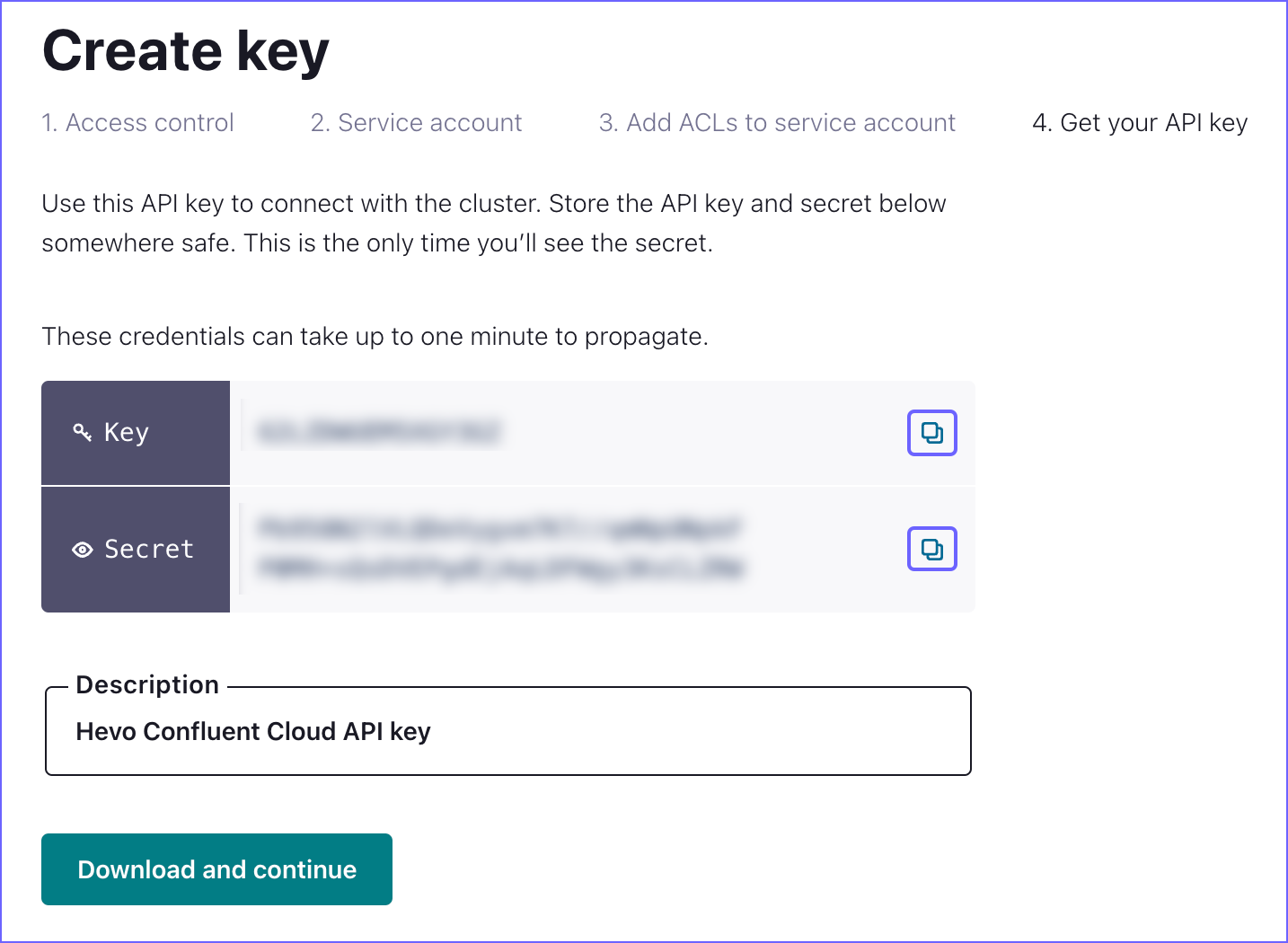
-
You can use these credentials while configuring your Hevo Pipeline.
Configure Kafka Confluent Cloud Connection Settings
Perform the following steps to configure Kafka Confluent Cloud as a Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Kafka Confluent Cloud.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Kafka Confluent Cloud Source page, specify the following:
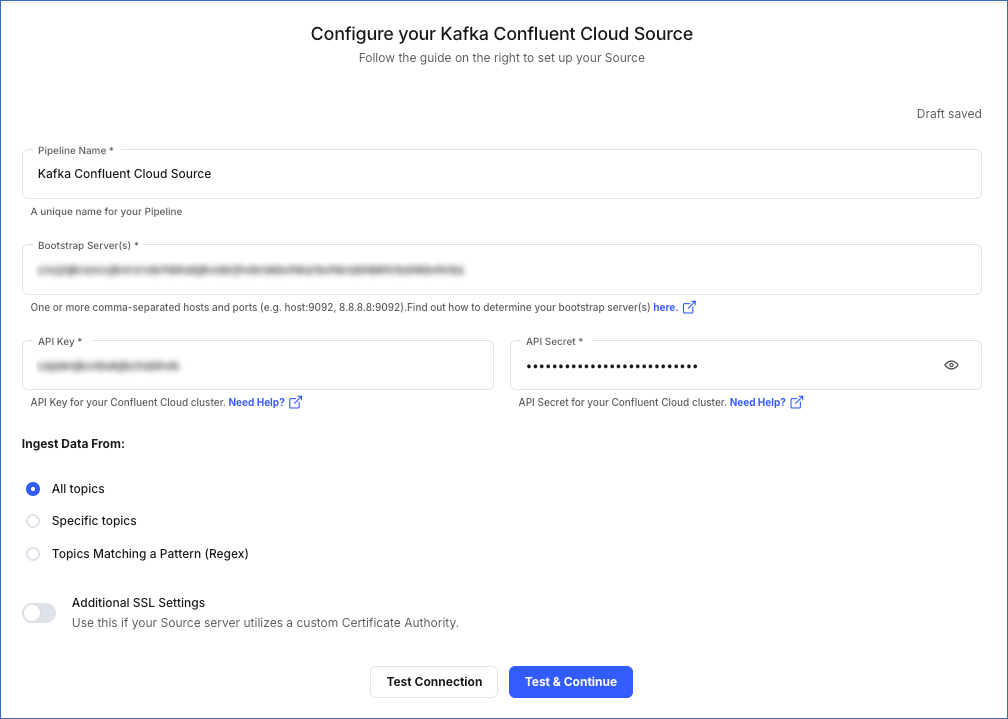
-
Pipeline Name - A unique name for your Pipeline, not exceeding 255 characters.
-
Bootstrap Server(s): The bootstrap server(s) extracted from Kafka Confluent Cloud.
-
API Key: The API key for your Kafka Confluent Cloud account.
-
API Secret: The API secret for your Kafka Confluent Cloud account.
-
Ingest Data From
-
All Topics: Select this option to ingest data from all topics. Any new topics that are created are automatically included.
-
Specific Topics: Select this option to manually specify a comma-separated list of topics. New topics are not automatically added in this option.
-
Topics Matching a Pattern (Regex): Select this option to specify a Regular Expression (regex) to match and select the topic names. This option also fetches data for new topics that match the pattern dynamically. You can test your regex patterns here.
-
-
Additional SSL Settings: (Optional) Enable this option if you are using a custom Certificate Authority (CA).
- CA File: The file containing the CA of the SSL server.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 1 Hr | NA |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
- Incremental Data: Once the Pipeline is created, all new and updated records are synchronized with your Destination as per the ingestion frequency.
If you restart an object via the Pipeline UI, Hevo ingests all the data available at that time in the Source.
For records that are structured as a list of records, Hevo ingests each record as an individual record. Each child record contains a common field called ref_id which is used to indicate a common parent record.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo only supports SASL_SSL-encrypted data in Kafka Confluent Cloud.
-
Hevo supports only JSON data format in Kafka Confluent Cloud.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-11-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configure Kafka Confluent Cloud Connection Settings as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-03-2023 | NA | Updated the page as per the latest Confluent Cloud user interface (UI). |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Sep-19-2022 | NA | Added section, Data Replication. |