Oracle database is a cross-platform Relational Database Management System (RDBMS) that can run on various hardware across operating systems including Windows Server, Unix, and various distributions of GNU/Linux. It is commonly referred to as Oracle database, OracleDB, or simply Oracle. The database software endorses transaction processing, business intelligence and different analytics applications, and used by both small and large enterprises to store and manage data.
Prerequisites
-
Oracle database version is 11 or above. You can retrieve the version of your Oracle database with the following command:
SELECT BANNER_FULL FROM V$VERSION WHERE BANNER_FULL LIKE 'Oracle Database%'; -
Redo Log-based replication is enabled when the ingestion mode is RedoLog and the database user has SYSDBA privileges.
Note: Hevo supports Redo Log ingestion mode for Oracle database 19c and higher in Pipelines created after Release 1.96.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Perform the following steps to configure your Generic Oracle Source:
Create a Database User and Grant Privileges
Connect to your Oracle server as a database administrator (DBA) using SQL Developer or any other SQL client tool and run the following script. This script creates a new database user in your Oracle database with access to the metadata tables and LogMiner. Keeping your privacy in mind, it grants only the necessary permissions required by Hevo to ingest data from your Oracle database.
-- Create a Database User
CREATE USER <username> IDENTIFIED BY <password>;
-- Grant Privileges to the Database User
GRANT SELECT ANY DICTIONARY to <username>;
GRANT CREATE SESSION, ALTER SESSION TO <username>;
GRANT SELECT ON ALL_VIEWS TO <username>;
GRANT SELECT ON <schema_name>.<table_name> TO <username>;
-- Grant Privileges on Metadata tables
GRANT SELECT ON DATABASE_PROPERTIES TO <username>;
GRANT SELECT ON ALL_OBJECTS TO <username>;
GRANT SELECT ON ALL_TABLES TO <username>;
GRANT SELECT ON ALL_TAB_COLUMNS TO <username>;
GRANT SELECT ON ALL_CONSTRAINTS TO <username>;
GRANT SELECT ON ALL_CONS_COLUMNS TO <username>;
-- Grant Permission to run LogMiner
GRANT LOGMINING TO <username>
GRANT SELECT ON SYS.V_$DATABASE TO <username>;
GRANT SELECT ON SYS.V_$LOG TO <username>;
GRANT SELECT ON SYS.V_$LOGFILE TO <username>;
GRANT SELECT ON SYS.V_$ARCHIVED_LOG TO <username>;
GRANT SELECT ON SYS.V_$LOGMNR_CONTENTS TO <username>;
GRANT SELECT ON SYS.V_$ARCHIVE_DEST_STATUS TO <username>;
GRANT EXECUTE ON SYS.DBMS_LOGMNR TO <username>;
GRANT EXECUTE ON SYS.DBMS_LOGMNR_D TO <username>;
Note: Replace the placeholder values in the commands above with your own. For example, <username> with hevo.
Refer to the table below for more information about these commands:
| Command | Grants access to |
|---|---|
| GRANT SELECT ANY DICTIONARY to <username>; | Query the data dictionary. This allows you to retrieve information about the database’s structure and metadata. |
| GRANT CREATE SESSION, ALTER SESSION TO <username>; | Create sessions and alter session settings. |
| GRANT SELECT ON ALL_VIEWS TO <username>; | Select data from all the views in the database. |
| GRANT SELECT ON <schema_name>.<table_name> TO <username>; | Select data from a specific table within a specific schema. |
| GRANT SELECT ON DATABASE_PROPERTIES TO <username>; | Retrieve information about the database properties from the configuration settings. |
| GRANT SELECT ON ALL_OBJECTS TO <username>; | Select data from all the objects in the database. |
| GRANT SELECT ON ALL_TABLES TO <username>; | Select data from all the tables in the database. |
| GRANT SELECT ON ALL_TAB_COLUMNS TO <username>; | Select columns from all the tables in the database. |
| GRANT SELECT ON ALL_CONSTRAINTS TO <username>; | Fetch information about all the constraints defined in the database. |
| GRANT SELECT ON ALL_CONS_COLUMNS TO <username>; | Fetch information about the table constraints. |
| GRANT LOGMINING TO <username>; | LogMiner to analyze and extract information from the redo log files. |
| GRANT SELECT ON SYS.V_$DATABASE TO <username>; | Query information from the V_$DATABASE data dictionary view in the SYS schema. |
| GRANT SELECT ON SYS.V_$LOG TO <username>; | Select data from the V_$LOG view in the SYS schema. |
| GRANT SELECT ON SYS.V_$LOGFILE TO <username>; | Select data from the V_$LOGFILE view in the SYS schema. |
| GRANT SELECT ON SYS.V_$ARCHIVED_LOG TO <username>; | Query information from the V_$ARCHIVED_LOG view in the SYS schema. |
| GRANT SELECT ON SYS.V_$LOGMNR_CONTENTS TO <username>; | Select data from the V_$LOGMNR_CONTENTS view in the SYS schema. |
| GRANT SELECT ON SYS.V_$ARCHIVE_DEST_STATUS TO <username>; | Select data from the V_$ARCHIVE_DEST_STATUS view in the SYS schema. |
| GRANT EXECUTE ON SYS.DBMS_LOGMNR TO <username>; | Run procedures and functions from the DBMS_LOGMNR package in the SYS schema. |
| GRANT EXECUTE ON SYS.DBMS_LOGMNR_D TO <username>; | Run procedures and functions defined in the DBMS_LOGMNR_D package in the SYS schema. Note: This privilege is required for starting and stopping LogMiner, adding redo log files for analysis, querying change data, and managing LogMiner sessions effectively. |
Set up Redo Logs for Replication
Connect to your Oracle server as a user with SYSDBA privileges using SQL Developer or any other SQL client tool and perform the following steps:
1. Enable Archive Log
Archive logs are essential for backup and recovery processes of a database management system.
Enter the command below to verify the current archive log mode:
SELECT LOG_MODE FROM V$DATABASE;
This query returns either of the following values:
-
ARCHIVELOG: Indicates that the archive log is enabled. -
NOARCHIVELOG: Indicates that the archive redo is disabled.
If the archive mode is NOARCHIVELOG, enable it using the following commands:
-
Enter the command below to initiate the shutdown process without waiting for active sessions or transactions to complete. It forcefully terminates existing connections.
SHUTDOWN IMMEDIATE; -
Enter the command below to start the Oracle database instance in a mounted state:
STARTUP MOUNT; -
Enter the command below to alter the database and enable archive log mode. This command instructs the database to start archiving the redo log files:
ALTER DATABASE ARCHIVELOG; -
Enter the command below to open the database for operations after enabling ARCHIVELOG mode:
ALTER DATABASE OPEN;
2. Configure the Retention Policy
The Recovery Manager (RMAN) retention policy determines how long the database holds backlogs and archive logs.
-
Run the following command to connect to the RMAN:
RMAN CONNECT TARGET <database_username> -- (to connect to your database)Note: Replace the placeholder values in the commands above with your own. For example, <database_username> with jacobs.
-
Run the following command to view the log retention policy:
SELECT VALUE FROM V$RMAN_CONFIGURATION WHERE NAME = 'RETENTION POLICY'; -
If the log retention policy is less than 3 days, run the following command to configure it to 3 days (72 hours):
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 3 DAYS;Note: We recommend setting the archive log retention policy to at least 3 days (72 hours). This avoids any data loss that may occur due to downtimes in the Source database.
3. Enable Supplemental Logging
Supplemental logging ensures that any changes in columns are logged in Redo log files, which is essential for LogMiner to access the activity history of a database.
-
Check if supplemental logging is enabled:
SELECT SUPPLEMENTAL_LOG_DATA_MIN FROM "V$DATABASE";This query returns either of the following values:
-
YES: Indicates that supplemental logging is enabled. -
NO: Indicates that supplemental logging is disabled.
-
-
If the result of query above is NO, enable supplemental logging at the database level with the following command:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;-
Enter the following command to retrieve the status of table-level supplemental logging:
SELECT COUNT(*) FROM ALL_LOG_GROUPS WHERE LOG_GROUP_TYPE='ALL COLUMN LOGGING' AND OWNER= '<group_name>' AND TABLE_NAME='<table_name>';Note: Replace the placeholder values in the commands above with your own. For example, <group_name> with jacobs.
This returns one of the following values:
-
<number>: The number of log groups for which supplemental logging is enabled. -
zero: This represents that the supplemental logging is disabled.
-
-
If the result of the above query is zero, enable supplemental logging for all columns of a specific table present in your Source database:
ALTER TABLE <SCHEMA_NAME>.<TABLE_NAME> ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-
4. Check PGA/SGA Memory Settings (Recommended)
In Oracle, the PGA memory settings allow you to manage and optimize memory usage for individual user processes involved in SQL execution.
-
Enter the command below to retrieve information about the initialization parameters ‘pga_aggregate_limit’ and ‘pga_aggregate_target’ from the
V$PARAMETERview:SELECT NAME, VALUE/1024/1024 as VALUE_MB FROM V$PARAMETER WHERE NAME IN ('pga_aggregate_limit', 'pga_aggregate_target');The following is an explanation of the command above:
-
SELECT NAME, VALUE/1024/1024 as VALUE_MB: This part retrieves data for the columns NAME and VALUE from the dynamic performance view V$PARAMETER. It retrieves theNAMEcolumn as is and calculates theVALUEcolumn divided by 1024 twice to convert the value from bytes to megabytes. It aliases the result as VALUE_MB. -
WHERE NAME IN ('pga_aggregate_limit', 'pga_aggregate_target'): This part filters the results to include only the rows where theNAMEcolumn is eitherpga_aggregate_limitorpga_aggregate_target.
-
-
Enter the command below to monitor the current PGA memory usage in your Oracle database:
SELECT NAME, VALUE, UNIT FROM V$PGASTAT WHERE NAME IN ('total PGA inuse','total PGA allocated');The following is an explanation of the command above:
-
SELECT NAME, VALUE, UNIT: This part retrieves data for the columns NAME, VALUE, and UNIT from the dynamic performance view V$PGASTAT. It retrieves the PGA statistic name, its value, and the unit for the value. -
WHERE NAME IN ('total PGA inuse', 'total PGA allocated'): This part filters the results to include only the rows where theNAMEcolumn is eithertotal PGA inuseortotal PGA allocated.
-
Oracle Buffers
In Oracle, buffers refer to memory storage for caching data to enhance database performance. When LogMiner reads data from redo log files, it utilizes the native in-memory Oracle buffer to cache ongoing transactions (ones that have not been committed or rolled back).
Data Manipulation Language (DML) operations within a transaction are buffered until a commit or rollback is detected. A long-running transaction can have a negative impact on the database performance. It can lead to increased lag in processing change events and memory usage on the database server.
This accumulation of data in the Oracle LogMiner buffers can lead to increased Program Global Area (PGA) memory consumption in your database. Therefore, it is essential to appropriately set the PGA memory size based on your database workload. Read Check PGA/SGA Memory Settings to review the memory settings and configure the PGA_AGGREGATE_LIMIT to prevent server OutOfMemory (OOM) errors.
Additionally, you can modify the Long Transaction Window while configuring your Source in Hevo based on the available PGA memory in your database. Any transactions exceeding this window are discarded entirely, which may lead to a data mismatch. Further, setting an excessively large value may cause OOM issues. Only your DBA can determine if your database has long-running transactions with a large number of changes. If so, set the PGA_AGGREGATE_LIMIT to an appropriate value to process these transactions.
5. Configure the PGA Aggregate Limit (Recommended)
It is important to set up the PGA aggregate limit for managing and controlling memory usage in individual user sessions and queries. Depending on your database workload, you can set the pga_aggregate_limit parameter to prevent out-of-memory errors. To do this, enter the following command:
ALTER SYSTEM SET pga_aggregate_limit = <new value> SCOPE=BOTH;
Note:
-
You can set the above value in one of the following units of measurement:
-
Krepresents kilobytes. -
Mrepresents megabytes. -
Grepresents gigabytes.
-
-
Replace the placeholder value in the command above with your own. For example, <new value> with 1G.
Retrieve the Service Name
Service name represents an alias of the unique Oracle database to which Hevo connects.
To retrieve the Service Name, open your Oracle server in any SQL client tool as a database user with SYSDBA privilege and enter the following command:
select name from v$database;
Connect to a Local Database (Optional)
Refer to the steps in this section if you need to connect to your local database. For detailed information and troubleshooting help, read Connecting to a Local Database.
Prerequisites
-
Oracle service is running on your local machine.
-
Data to be loaded to the Destination is available in your Oracle database.
-
You have an account on ngrok and an installed ngrok utility on your local machine. To run ngrok on your local machine, follow these one-time steps:
-
Extract the ngrok utility:
-
On Linux or MacOS, unzip ngrok from a terminal:
unzip /path/to/ngrok.zip -
On Windows, double-click ngrok.zip to extract it.
-
-
Authenticate ngrok in your local machine:
./ngrok authtoken <your_auth_token>You can get the auth token from your ngrok dashboard. For example, in the image below, the auth_token starts with
2ig3VXv3v2ZX4LDg.
-
Connect to your local database
Perform the following steps to connect to the local database:
-
Log in to your database server.
-
Start a TCP tunnel forwarding to your database port.
./ngrok tcp <your_database_port>For example, the port address for MySQL is 3306. Therefore, the command would be:
./ngrok tcp 3306 -
Copy the public IP address (hostname and port number) for your local database and port. For example, in the image below,
8.tcp.ngrok.iois the database hostname and19789is the port number.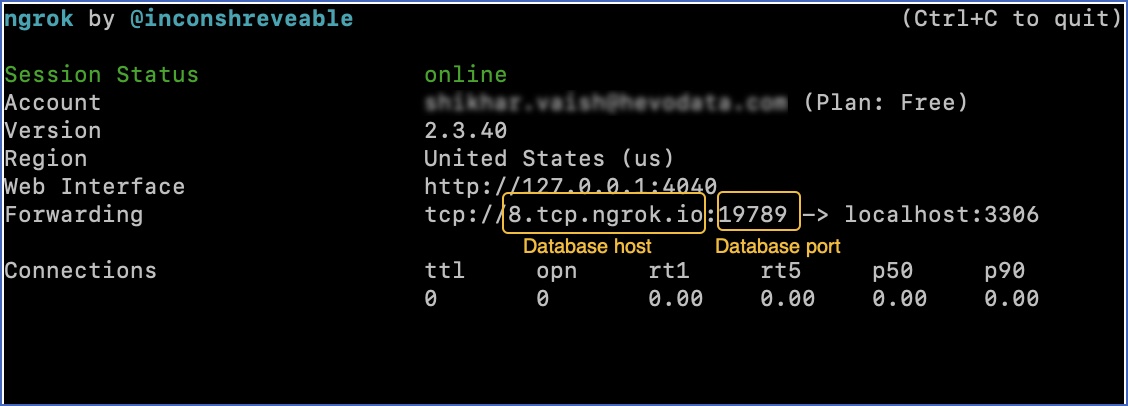
-
Paste the hostname and port number into the Database Host and Database Port fields respectively.

-
Specify all other settings and click Test & Continue.
Specify Oracle Connection Settings
Perform the following steps to configure Oracle as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Oracle.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the page that appears, do the following:

-
Select Pipeline Mode: Choose the mode for ingesting data from the Source. Default value: RedoLog. The available modes are RedoLog, Table, and Custom SQL.
Depending on the Pipeline mode you select, you must configure the objects to be replicated. Refer to section, Object and Query Mode Settings for the steps to do this.
Note: For Custom SQL Pipeline mode, all Events loaded to the Destination are billable.
-
Select Pipeline Type: Choose the type of Pipeline you want to create based on your requirements, and then click Continue.
-
If you select Edge, read Generic Oracle to configure your Edge Pipeline.
-
If you select Standard, skip to step 6 below.
This section is displayed only if all the following conditions are met:
-
The selected Destination type is supported in Edge.
-
The Pipeline mode is set to RedoLog.
-
Your Team was created before September 15, 2025, and has an existing Pipeline created with the same Destination type and Pipeline mode.
For Teams that do not meet the above criteria, if the selected Destination type is supported in Edge and the Pipeline mode is set to RedoLog, you can proceed to create an Edge Pipeline. Read Generic Oracle to configure your Edge Pipeline. Otherwise, you can proceed to create a Standard Pipeline.
-
-
-
On the Configure your Oracle Source page, specify the following:

-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Database Host: The Oracle database host’s IP address or DNS.
The following table lists few examples of Oracle hosts:
Variant Host Amazon RDS Oracle oracle-rds-1.xxxxx.rds.amazonaws.com Generic Oracle 192.168.2.5 Note: For URL-based hostnames, exclude the http:// or https:// part. For example, if the hostname URL is https://oracle-rds-1.xxxxx.rds.amazonaws.com, enter oracle-rds-1.xxxxx.rds.amazonaws.com.
-
Database Port: The port on which your Oracle server listens for connections. Default value: 1521.
-
Database User: The authenticated user who has the permissions to read tables in your database.
-
Database Password: The password for the database user.
-
Service Name: An alias of the unique Oracle database to which Hevo connects. To retrieve the Service Name, open your Oracle server in any SQL client tool as a database user with
SYSDBAprivilege and enter the following command:select name from v$database; -
Owner: The name of the schema owner to identify the schemas for ingesting the data. Data of all the schemas defined by the specified owner are ingested for replication. This is required if ingestion mode is Table or Custom SQL.
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your Oracle database host to Hevo. This provides an additional level of security to your database by not exposing your Oracle setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses to allow Hevo to connect to your Oracle database host. Refer to the content for your Oracle variant for steps to do this.
-
Redo Log Advanced Settings: This section is applicable if RedoLog is selected as an ingestion mode:
Note: Any modification in the default value of the following settings may impact your database performance. We recommend that you contact Hevo Support before making any changes.
-
Poll Interval (in ms): The delay in milliseconds between the checks that Hevo makes to search for new transactions in the redo logs. Default value: 500.
-
Query Fetch Size: The maximum number of rows that Hevo fetches from the logs in each query. Default value: 10,000.
-
Long Transaction Window (in mins): The duration in minutes that Hevo must traverse back from the current transaction to fetch the data in a long-running transaction. Default value: 5.
Note: Increasing the default value can lead to increased memory consumption by the Source database during log mining sessions.
-
-
Load All Schemas: If enabled, Hevo loads data for all the schemas.
If disabled, Hevo loads data from the schema(s) that you specify in a comma-separated list.
-
Online Catalog: If enabled, Hevo retrieves the updated schema information from the specified Oracle database. This setting is ideal when schema changes are infrequent or nonexistent in the database tables.
If disabled, Hevo retrieves the schema information from the copy that Hevo maintains.
Note: This option is non-editable post-Pipeline creation.
-
Archive Log Only: If enabled, Hevo ingests data only from the archived redo logs.
If disabled, Hevo ingests data from the archived and online redo logs.
-
Advanced Settings:
-
Load Historical Data: Applicable for Pipelines created with RedoLog or Table mode. If this option is enabled, the entire table data is fetched during the first run of the Pipeline. If disabled, Hevo loads only the records written to your database after the Pipeline was created.
-
Merge Tables: Applicable for Pipelines with RedoLog mode. If this option is enabled, Hevo merges tables with the same name from different databases while loading the data to the warehouse. Hevo loads the Database Name field with each record. If disabled, the database name is prefixed to each table name. Read How does the Merge Tables feature work?.
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source. All data for these tables is ingested using database logs, making it incremental and therefore billable.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
-
-
-
Click Test Connection. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click Test & Continue to proceed for setting up the Destination. This button is enabled once you specify all the mandatory fields.
Object and Query Mode Settings
Once you have specified the Source connection settings in Step 5 above, do one of the following:
-
For Pipelines configured with the Table or RedoLog mode:
-
On the Select Objects page, select the objects you want to replicate and click Continue.

Note:
-
Each object represents a table in your database.
-
From Release 2.19 onwards, for log-based Pipelines, you can keep the objects listed on the Select Objects page deselected by default. In this case, when you skip object selection, all objects are skipped for ingestion, and the Pipeline is created in the Active state. You can include the required objects post-Pipeline creation. Contact Hevo Support to enable this option for your teams.
-
-
On the Configure Objects page, specify the query mode you want to use for each selected object.

-
-
For Pipelines configured with the Custom SQL mode:
-
On the Provide Query Settings page, enter the custom SQL query to fetch data from the Source.
-
In the Query Mode drop-down, select the query mode, and click Continue.

-
Data Replication
| For Teams Created | Ingestion Mode | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|---|
| Before Release 2.21 | Table | 15 Mins | 5 Mins | 24 Hrs | 1-24 |
| Log-based | 5 Mins | 5 Mins | 1 Hr | NA | |
| After Release 2.21 | Table | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
| Log-based | 30 Mins | 30 Mins | 12 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Redo Log does not support user-defined data types. Therefore, fields with such data types are not captured in the log and are lost.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Oct-13-2025 | NA | Updated section, Specify Oracle Connection Settings to clarify when the Select Pipeline Type section is displayed during Pipeline configuration. |
| Oct-09-2025 | NA | Updated section, Specify Oracle Connection Settings to mention that the Load Historical Data option is also applicable for Pipelines created with Table mode. |
| Sep-18-2025 | NA | Updated section, Specify Oracle Connection Settings as per the latest UI. |
| Aug-1-2025 | NA | Added clarification that data ingested from new and re-created tables is billable. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-30-2025 | NA | Renamed the section, Configure the Retention Period to Configure the Retention Policy and added a command to view the archive log retention policy. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Oct-22-2024 | NA | Updated sections, Connect to a Local Database (Optional) and Specify Oracle Connection Settings as per the latest Hevo UI. |
| Apr-29-2024 | NA | Updated section, Specify Oracle Connection Settings to include more detailed steps. |
| Apr-19-2024 | NA | Revamped the page content for clarity and coherence. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Jan-22-2024 | 2.19.2 | Updated section, Object and Query Mode Settings to add a note about the enhanced object selection flow available for log-based Pipelines. |
| Jan-10-2024 | 2.19 | Updated section, Specify Oracle Connection Settings as per latest Hevo functionality. |
| Nov-03-2023 | NA | Added section, Object and Query Mode Settings. |
| Oct-09-2023 | NA | Added section, Configure the PGA Aggregate Limit. |
| Apr-21-2023 | NA | Updated section, Specify Oracle Connection Settings to add a note to inform users that all loaded Events are billable for Custom SQL mode-based Pipelines. |
| Mar-09-2023 | 2.09 | Updated section, Specify Oracle Connection Settings to mention about SEE MORE in the Select an Ingestion Mode section. |
| Dec-19-2022 | 2.04 | Updated section, Specify Oracle Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Dec-07-2022 | 2.03 | Updated section, Specify Oracle Connection Settings to mention about including skipped objects post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Specify Oracle Connection Settings to mention about the connectivity checker. |
| Jun-16-2022 | NA | Added section, Connecting to a Local Database. |
| Dec-06-2021 | 1.77 | Added a See Also link to the Pipeline failure due to Redo Log expiry page. |
| Nov-22-2021 | NA | Updated the Limitations section. |
| Feb-22-2021 | 1.57 | Added sections: - Create a User and Grant Privileges - Retrieve the Service Name |