Hive is a cloud-based project management and collaboration platform that allows businesses to manage their projects. It enables you to create and assign tasks, communicate with other Hive and external users, share files, and automate business processes by creating custom workflows.
Hive uses an API key to identify Hevo and authorize the request for accessing account data.
Prerequisites
-
An active Hive account from which data is to be ingested exists.
-
The API credentials are available to authenticate Hevo on your Hive account.
-
You are logged in as an Admin user to obtain the API credentials. Else, you can obtain these from your account administrator.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the API Credentials
You require the API credentials, namely, the Hive user ID, the API key, and the workspace ID, to authenticate Hevo on your Hive account.
Note: You must log in as an Admin user to perform these steps.
Perform the following steps to obtain these API credentials from your Hive account:
-
Log in to your Hive account.
-
In the top right corner, click on your username icon, and select My settings from the drop-down menu.
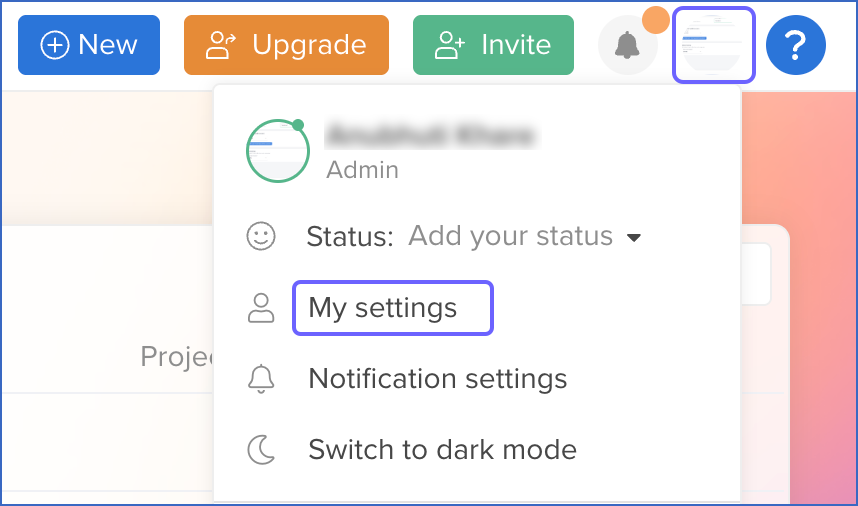
-
In the left navigation pane, click API info.
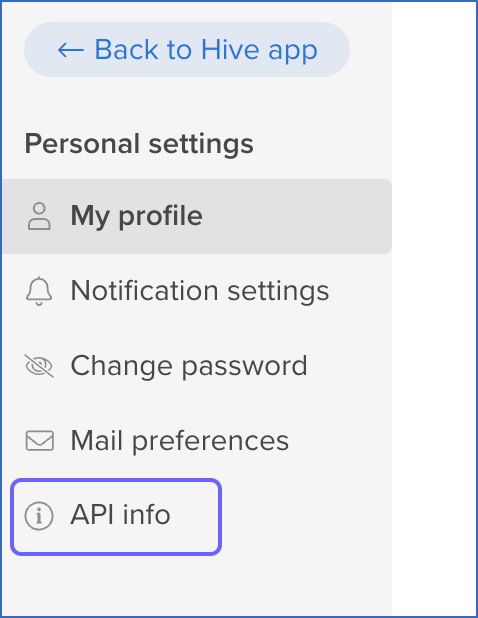
-
From the API info page, copy the API Key, User ID, and Workspace ID and save them securely like any other password.
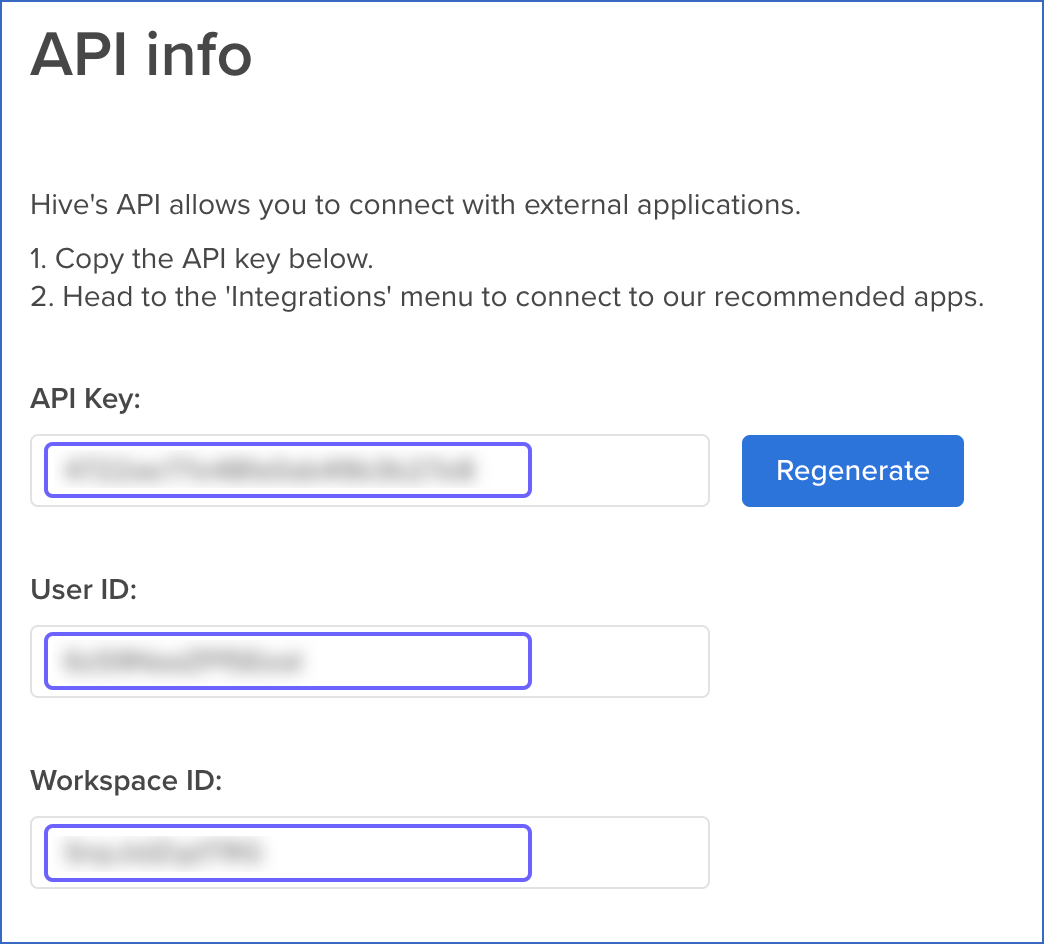
You can use these credentials while configuring your Hevo Pipeline.
Configuring Hive as a Source
Perform the following steps to configure Hive as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Hive.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Hive Source page, specify the following:
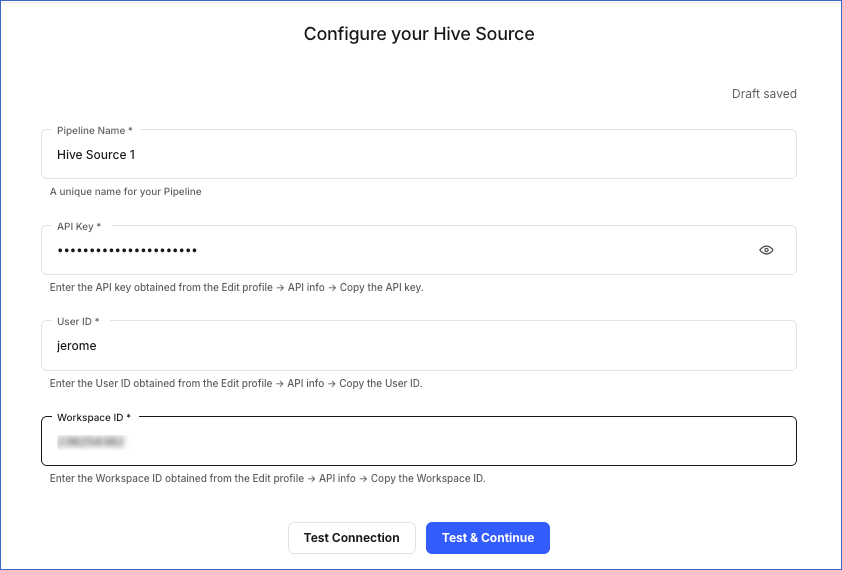
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
API Key: The API key that you obtained from your Hive account.
-
User ID: The user ID that you obtained from your Hive account.
-
Workspace ID: The ID of the Hive workspace from where you want to ingest data.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Hevo ingests all the objects in Full Load mode in each run of the Pipeline.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.
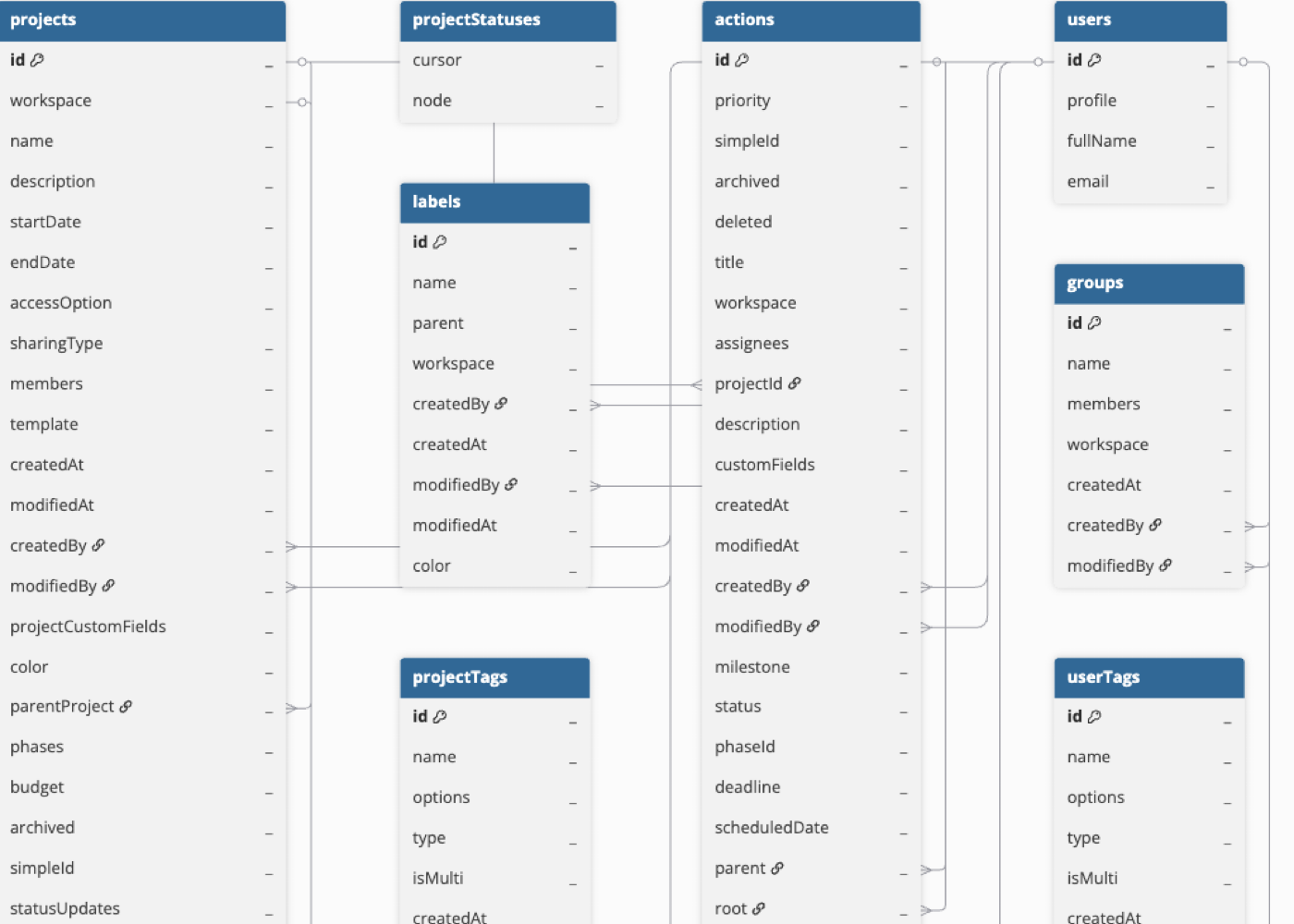
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Projects | Contains details about the containers used for organizing actions in your Hive account. |
| Actions | Contains details of the tasks assigned to different users in your Hive account. |
| Users | Contains details about the individuals who have access to log into your Hive account and manage certain features depending on their user permissions. |
| Teams | Contains details of the different user groups in your Hive account. |
| Labels | Contains details about the different color tags used to filter and sort actions in Hive. |
| Groups | Contains the list of all the chat groups created by users in your Hive account. |
| Custom Fields | Contains details of the customized fields added by a user to capture some additional data. |
| Project Statuses | Contains the list of current statuses of projects in your Hive account. |
| Resource Assignments | Contains details of the time windows allocated to users to complete certain projects. |
| Project Tags | Contains details about the tags assigned to projects. |
| Role Tags | Contains details about the roles that can be assigned to users to allow them to access features in Hive. |
| User Tags | Contains details of all the possible tags that a user can have in your Hive account. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Pagination: Each API call for a Hive object fetches one page with up to 200 records for Actions, Labels, Project Statuses & Project Assignments objects and 100 records for all other objects.
-
Rate Limit: Hive imposes a limit of 50 API calls per minute per account. If the limit is exceeded, Hevo defers the ingestion till the limits reset.
Limitations
-
Hevo does not capture information for records deleted in the Source objects.
-
The Resource Assignments, Project Tags, User Tags, and Role Tags objects are available only when Resourcing is enabled. Additionally, access to these objects requires a paid subscription in Hive.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Oct-27-2025 | NA | Updated section, Obtaining the API Credentials as per the latest Hive UI. |
| Sep-18-2025 | NA | Updated section, Configuring Hive as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-20-2022 | 2.04 | New document. |