Amplitude Analytics helps generate thorough product analytics of web and mobile application usages to help you make data driven decisions. You can replicate data from your Amplitude account to a database, data warehouse, or file storage system using Hevo Pipelines.
Note: Hevo fetches data from Amplitude Analytics in a zipped folder to perform the data query.
Prerequisites
-
An active Amplitude Analytics account with access to at least one project exists.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Retrieving the Amplitude API Key and Secret
You require an API key and a secret to authenticate Hevo on your Amplitude Analytics account.
-
Log in to your Amplitude account.
-
In the top right corner of the home page, click the Settings (
 ) icon, and then select Organization settings.
) icon, and then select Organization settings.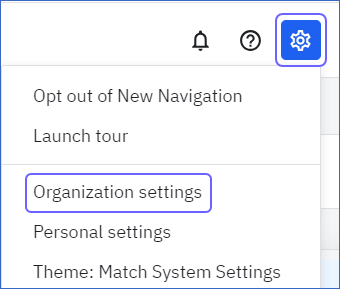
-
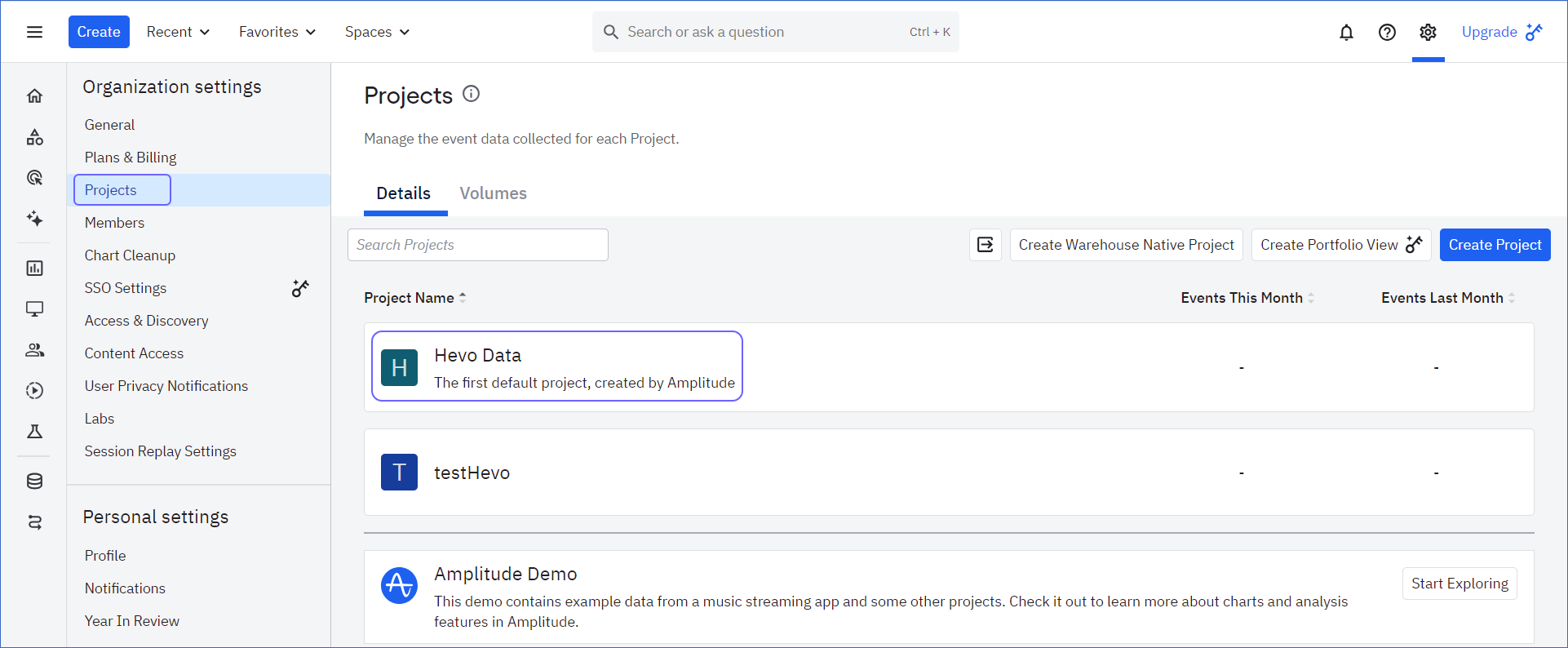
Under Organization settings, click Projects, and then select a project whose data you would like to sync.
-
Under the General tab, click Show to reveal the API Key and Secret Key. Copy and save them securely like any other password.
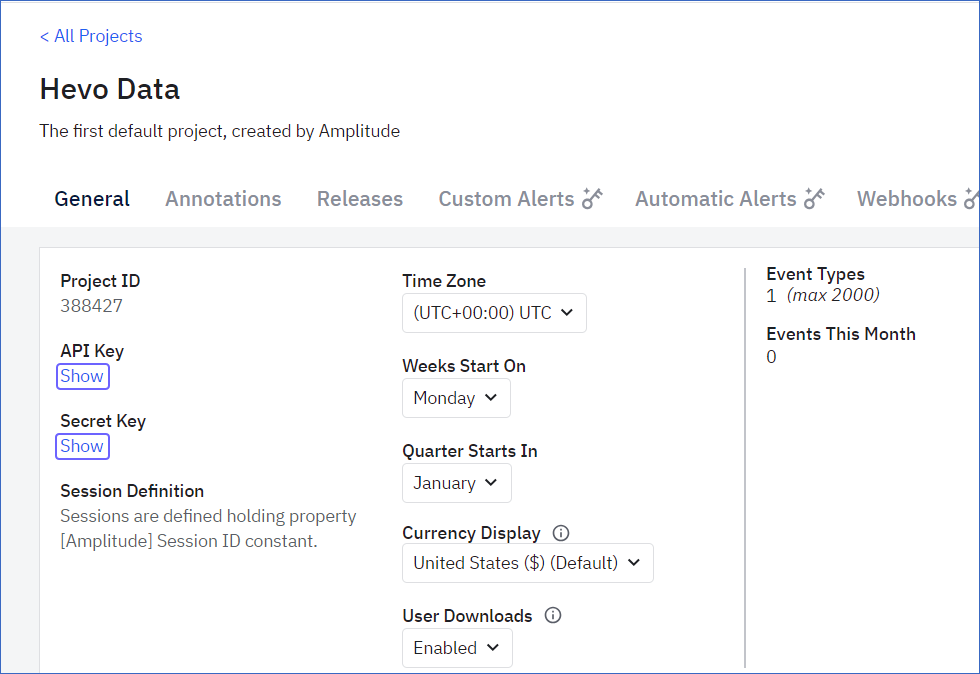
You can use these credentials while configuring your Hevo Pipeline.
Configuring Amplitude Analytics as a Source
Perform the following steps to configure Amplitude Analytics as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Amplitude Analytics.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
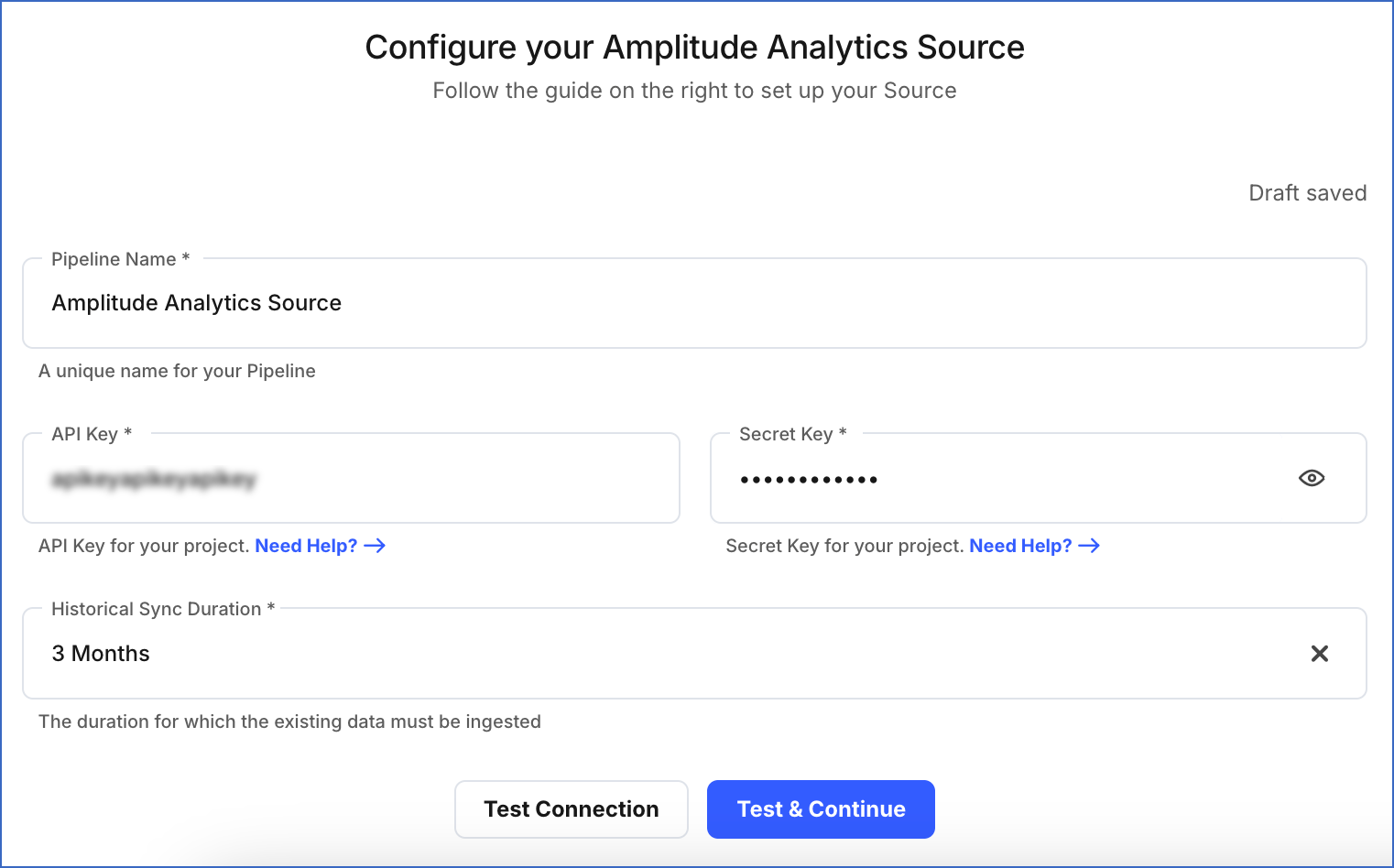
On the Configure your Amplitude Analytics Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline.
-
API Key: The API key you retrieved from your Amplitude account.
-
Secret Key: The secret key you retrieved from your Amplitude account.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source.This cannot be changed after the Pipeline is created. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Amplitude Analytics account since January 01, 2012.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data : The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 3 Months.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Note: The size of the zipped folder from the Source must not exceed 4 GB, else, the data query fails with an exception, Invalid CEN header. In the case of an exception, Hevo automatically adjusts the ingestion duration of the historical load and the incremental data, ingesting the data in smaller zip files over multiple cycles.
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline.
| Table Name | Description |
|---|---|
| Cohort | A list of all unique behavioural cohorts created within Amplitude |
| Event | An action that a user takes in your product. This could be anything from pushing a button, completing a level, or making a payment |
| Event Category | All event data is mapped to an Event Category entity which helps to categorise and describe live events and properties. |
| Event Type | All events are mapped to an Event Type entity which is maintained in this table. |
| Group | Each grouping of users that is created in Amplitude along with their dedicated name and description. |
| User | Any person who has logged at least one event and to whom events are attributed. |
| User Cohort | A mapping between User and the User Cohort they belong in. |
| User Group | Groups of users defined by their actions within a specific time period. |
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
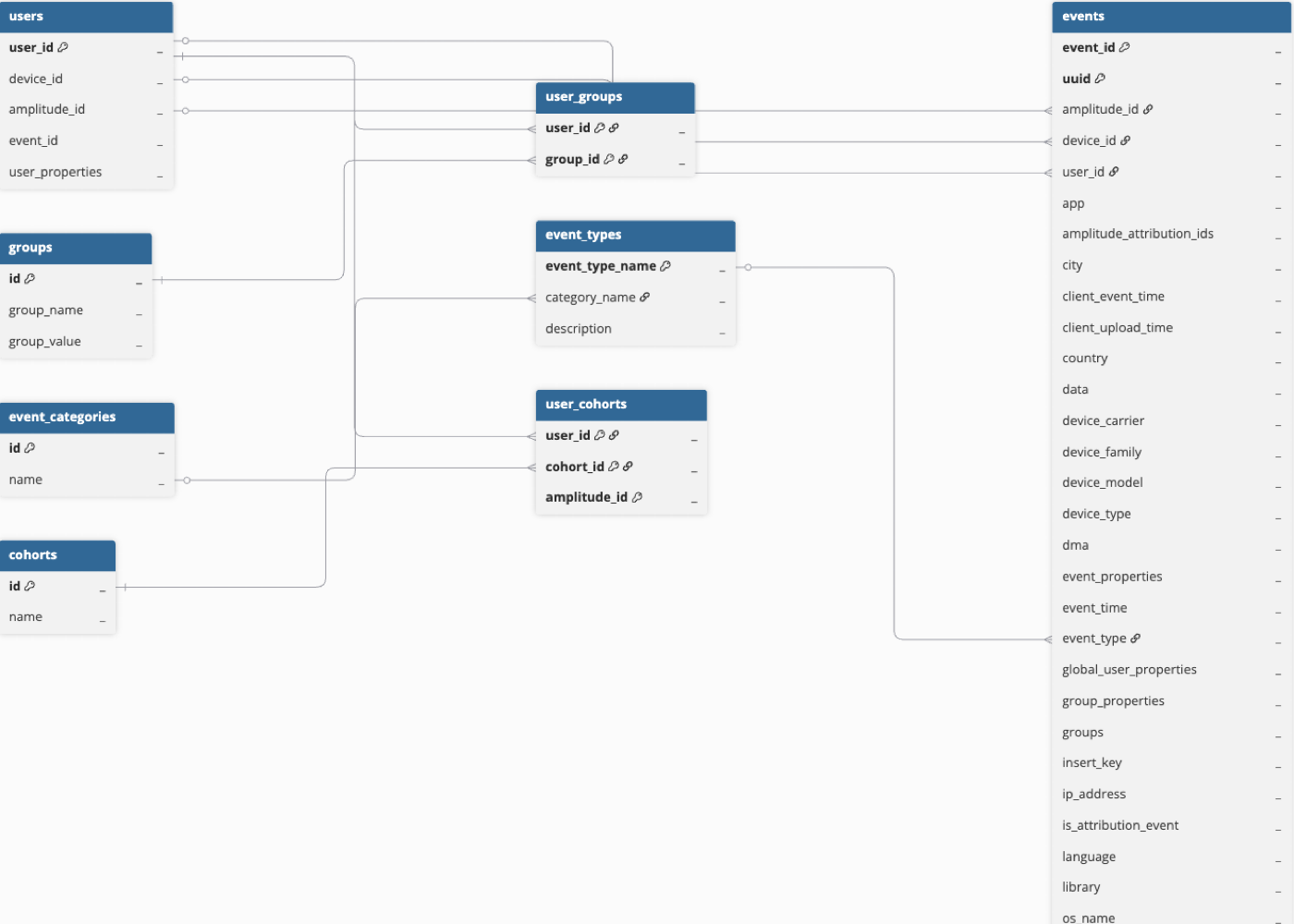
The User object defines each unique user through a combination of User ID, Amplitude ID, and Device ID. You can reference these three columns while making joins to the Event object.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Amplitude Analytics introduces a two-hour delay between receiving data and when that data becomes available for ingestion into Hevo via the Export API.
For example, data sent between 8–9 PM is uploaded to Amplitude Analytics at 9 PM and becomes available for ingestion at 11 PM.
-
Each Export API request in Amplitude Analytics has a 4GB size limit. If the data for a specific time range exceeds this limit, the API request fails, and Hevo cannot ingest any data for that period. This may result in data inconsistencies or Pipeline failures. To avoid such failures, increase the ingestion frequency so that data is ingested in smaller batches.
-
Users on the Growth and Enterprise plans can make up to 500 Behavioral Cohorts Download API requests per month to download cohorts. This API is not available to users on the Starter or Plus plans.
-
The Behavioral Cohorts Download API supports a maximum cohort size of 2 Million users.
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Amplitude Analytics as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Amplitude Analytics as a Source as per the latest UI. |
| Sep-15-2025 | NA | Added section, Source Considerations. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Nov-05-2024 | NA | Updated section, Retrieving the Amplitude API Key and Secret as per the latest Amplitude Analytics UI. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-04-2023 | NA | Updated section, Configuring Amplitude Analytics as a Source to update the information about historical sync duration. |
| Jun-21-2022 | 1.91 | - Modified section, Configuring Amplitude Analytics as a Source to reflect the latest UI changes. - Updated the Pipeline frequency information in the Data Replication section. |
| Mar-07-2022 | 1.83 | Updated the introduction paragraph and the section,Data Replication, about automatic adjustment of ingestion duration. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Apr-06-2021 | 1.60 | - Added a note to the section Schema and Primary Keys - Updated the ERD. The User object now has three fields, user_id, amplitude_id and device_id as primary keys. The field uuid in the Event object is also a primary key now. |