This Destination is currently available for Early Access. Please contact your Hevo account executive or the Support team to enable it for your team. Alternatively, request for early access to try out one or more such features.
Amazon Simple Storage Service (S3) is a durable, efficient, secure, and scalable cloud storage service provided by Amazon Web Services (AWS) that can be accessed from anywhere. S3 uses the concept of buckets to store data in multiple formats, such as images, videos, and documents, organize that data, and retrieve it at any time from the cloud. It also provides you access control, versioning, and integration with other AWS services.
Hevo can ingest data from any of your Pipelines and load it in near real-time to your S3 bucket using the Append Rows on Update mode. The ingested data is loaded as Parquet or JSONL files to the S3 buckets.
Note: As the data is stored in file format in the S3 bucket, you cannot view the Destination schema through the Schema Mapper or query the loaded data using the Workbench.
Hevo allows storing data in a compressed or uncompressed form in the S3 bucket. Refer to the table below for the supported compression algorithms:
If you are new to AWS or do not have an AWS account, follow the steps listed in the Create an AWS account section, and after that, Set up an Amazon S3 bucket. You can then configure the S3 bucket as a Destination in Hevo.
The following image illustrates the key steps required for configuring Amazon S3 as a Destination in Hevo:
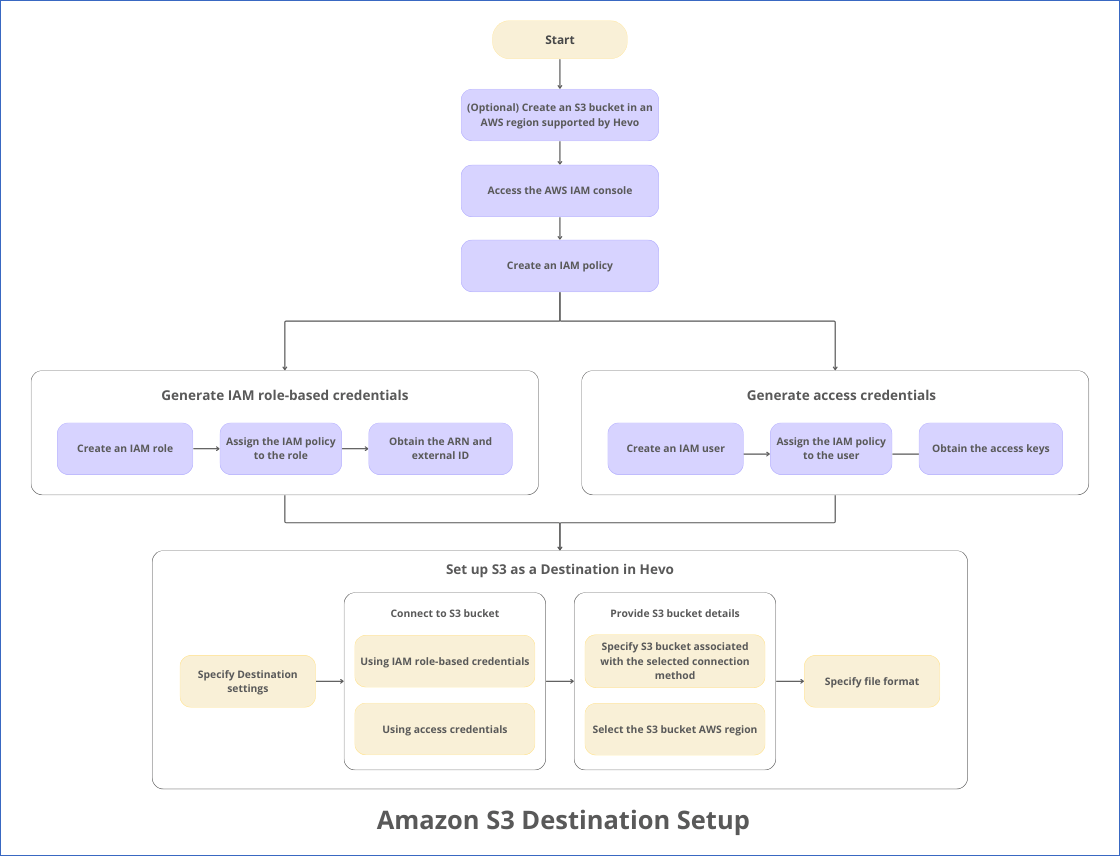
Prerequisites
-
You have an active AWS account and an IAM user in the account with permission to:
-
Create an IAM role (to generate the IAM role-based credentials) or create an IAM user (to generate the access credentials).
-
An Amazon S3 bucket in one of the supported AWS regions is available. Refer to the Create an Amazon S3 bucket section for the steps if you do not have one.
-
The IAM role-based credentials or access credentials are available to enable Hevo to connect to your S3 bucket.
-
You are assigned the Team Collaborator or any administrator role except the Billing Administrator role in Hevo to create the Destination.
Create an Amazon S3 Bucket (Optional)
Note: The following steps must be performed by a Root user or a user with administrative access. In AWS, permissions and roles are managed through the IAM page.
-
Log in to your AWS account and open the Amazon S3 console. Read Log in to your AWS instance for the steps to create an AWS account if you do not have one.
-
At the top right corner of the page, click your current AWS region, and from the drop-down list, select the region in which you want to create your S3 bucket. For example, Singapore. It is recommended that you co-locate your S3 bucket in the same region as your Hevo account for faster access.

-
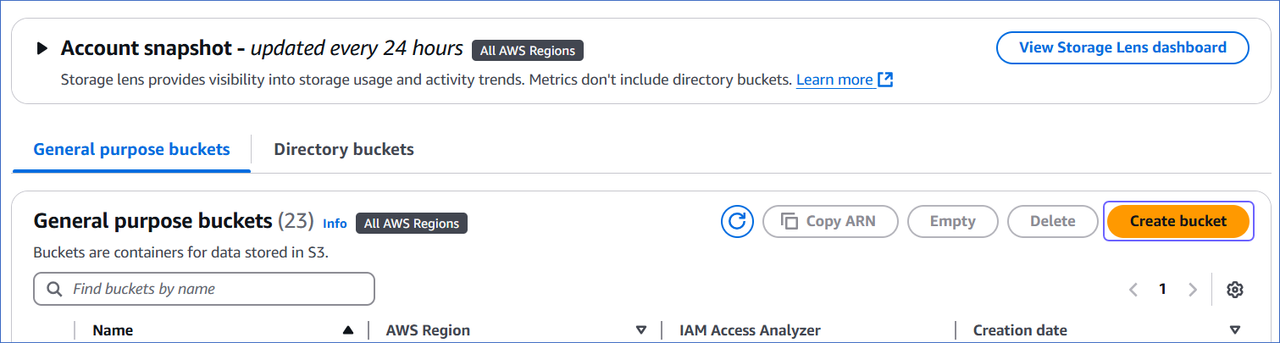
In the left navigation pane of your Amazon S3 dashboard, click General purpose buckets.

-
In the right pane, under the General purpose buckets tab, click Create bucket.
-
On the Create bucket page, General configuration section, do the following:

-
Ensure that the AWS Region in which you want to create your S3 bucket is the same as the one selected in Step 2.
Note: This field is non-editable.
-
Specify the following:
-
Bucket type: The type of S3 bucket you want to create. Ensure that General purpose is selected.
-
Bucket name: A unique name for your S3 bucket, not less than 3 characters and not exceeding 63 characters. Read Bucket naming rules for the conventions to follow while naming a bucket.
-
Copy settings from existing bucket - optional: Click Choose bucket to select an existing bucket and copy its settings to your bucket.
-
-
-
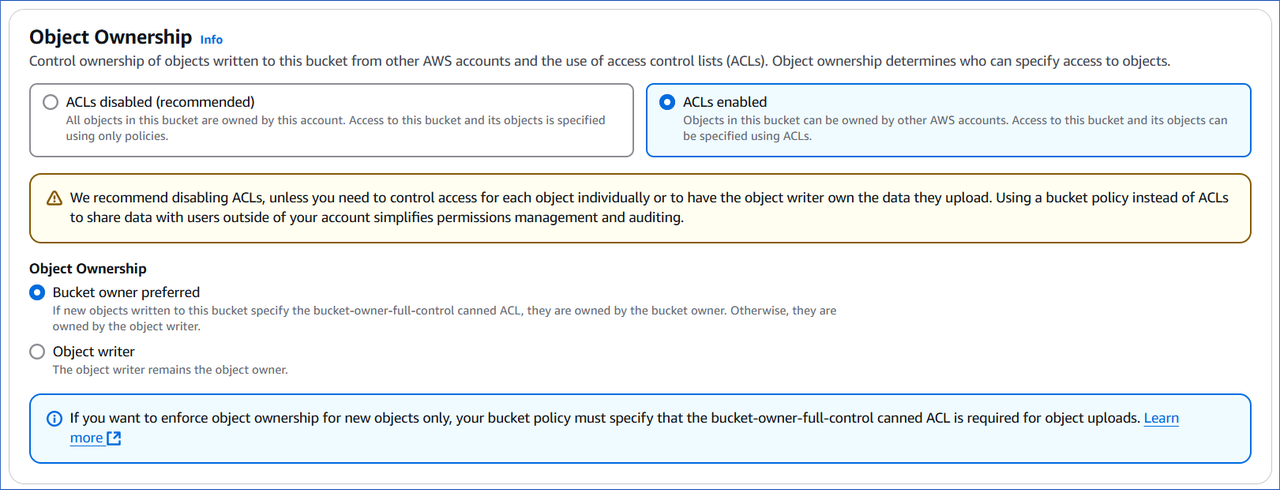
In the Object Ownership section, specify who can access the objects in your S3 bucket. Select one of the following:

-
ACLs disabled (recommended): All the objects in the S3 bucket are owned by the AWS account that created it.
- Bucket owner enforced (Default): As the bucket owner, you have full control over the objects created in the S3 bucket. You can grant other users access to the bucket and its objects through IAM user policies and S3 bucket policies.
-
ACLs enabled: The objects in the S3 bucket can be owned by other AWS accounts, and ownership is controlled through access control lists (ACLs). Based on how you want to enforce ownership, select one of the following:
-
Bucket owner preferred: As the bucket owner, you have full control over new objects uploaded to the bucket with the bucket-owner-full-control canned ACL specified. The object writer, or the AWS account, remains the owner of new objects uploaded without this ACL. The ownership of existing objects is not affected by this setting. Read Access control list for information on the ACLs supported by Amazon S3.
-
Object writer: The AWS account that uploads objects to the bucket remains the owner of those objects. With this option, as the bucket owner, you cannot grant access through bucket policies to the objects owned by other AWS accounts.
-
-
-
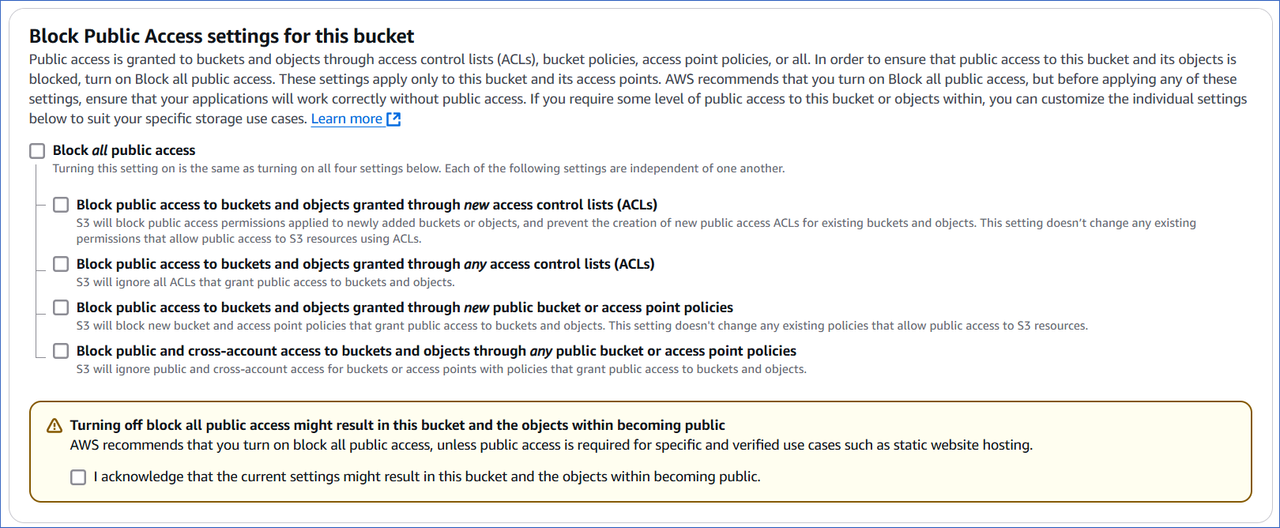
In the Block Public Access settings for this bucket section, do one of the following:
-
Select the Block all public access check box if you do not want the bucket and its objects to be publicly accessible. Default selection: Enabled.
-
Deselect the Block all public access check box to grant public access to the bucket and the objects within, or selectively block access to them. Read Blocking public access to your Amazon S3 storage to understand the individual options.
Note: If you turn off this setting, you must acknowledge the warning by selecting the I acknowledge that… check box.
-
-
(Optional) In the Bucket Versioning section, based on your requirements, specify one of the following:
-
Disable: Your bucket does not maintain multiple versions of an object, or is unversioned. This is the default selection.
-
Enable: Your bucket stores every version of an object, allowing you to recover objects in case they are accidentally deleted or overwritten.
Note: Once you enable versioning on a bucket, you cannot revert it. Versioning can only be suspended. Read Using versioning in S3 buckets to understand the feature.
-
-
(Optional) In the Tags section, specify a key-value pair to categorize the data stored in your bucket by its purpose. For example, to consolidate all your billing data in the bucket, specify the key as Billing and its value as True.
-
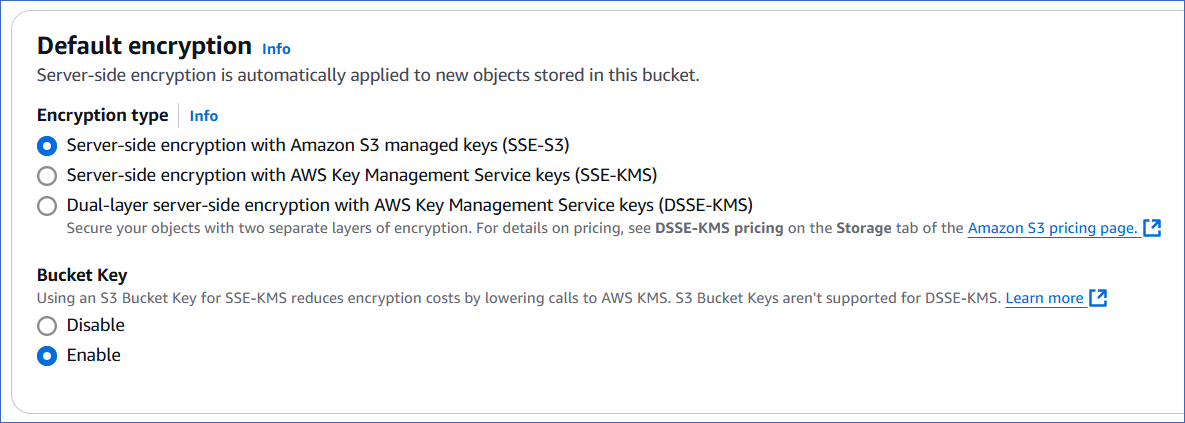
In the Default encryption section, specify the following:
-
Encryption type: The type of encoding you want Amazon S3 to apply on objects before storing them in the bucket. Server-side encryption is automatically applied to protect your stored data. Select from one of the following types:
-
Server-side encryption with Amazon S3 managed keys (SSE-S3) (Default): In this option, Amazon S3 manages the encryption and decryption process.
-
Server-side encryption with AWS Key Management Service keys (SSE-KMS): In this option, encryption is managed by AWS KMS. You can specify the default AWS managed key (aws/s3), select from one of the existing KMS keys, or create one at this time. Read Creating keys for the steps to add a new AWS KMS key.
-
Dual-layer server-side encryption with AWS Key Management Service keys (DSSE-KMS): In this option, two layers of encryption are applied to the objects by AWS KMS, which manages the encryption.
Note: At this time, Hevo supports only SSE-S3.
-
-
Bucket Key: A data key, with a short lifespan, generated by AWS from AWS KMS and kept in S3. Using a bucket key helps lower the encryption costs for SSE-KMS by reducing the traffic between S3 and AWS KMS. A bucket key is not required for SSE-S3 and is not supported by DSSE-KMS. For these encryption types, you must Disable bucket keys. Default selection: Enable.
-
-
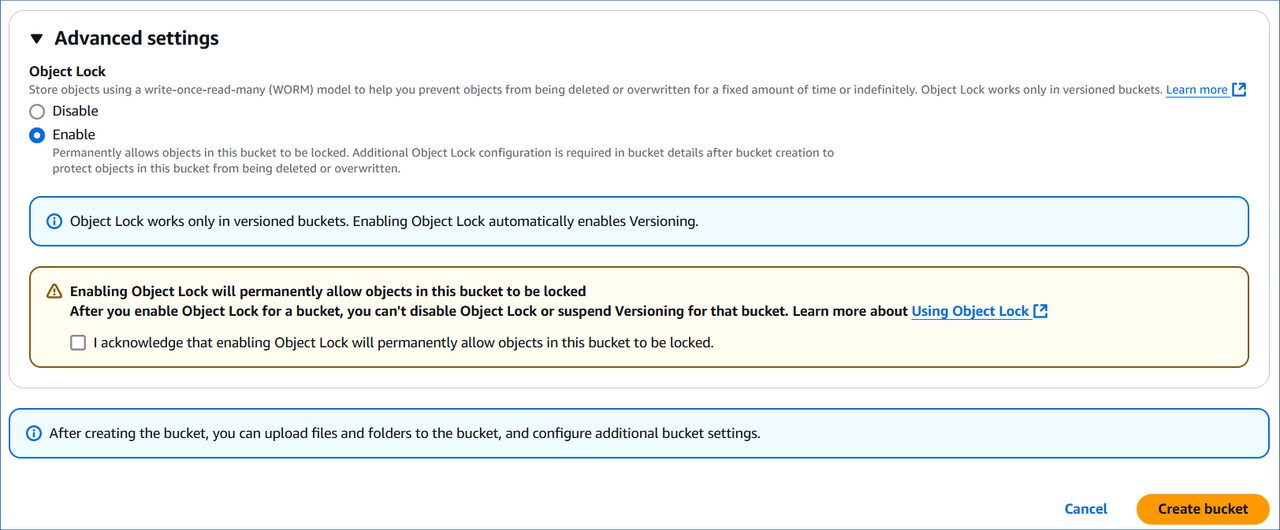
(Optional) In the Advanced settings, Object Lock section, specify one of the following:
-
Disable (Default): Objects uploaded to the bucket are not locked and can be deleted or overwritten.
-
Enable: Objects uploaded to the bucket are stored using the write-once-read-many (WORM) model, which prevents the objects from being deleted or overwritten. You must acknowledge the warning to enable object lock for your bucket.
Note: Object lock works only in versioned buckets. Thus, selecting this option automatically enables bucket versioning. Read Using S3 Object Lock to understand this feature.
-
-
Click Create bucket to create your Amazon S3 bucket. You can specify this bucket while configuring Amazon S3 as a Destination in Hevo.
Create an IAM Policy for the S3 Bucket
To allow Hevo to access your S3 bucket and load data into it, you must create an IAM policy with the following permissions:
| Permission Name | Allows Hevo to |
|---|---|
| s3:ListBucket | Check if the S3 bucket: - Exists. - Can be accessed and the objects in the bucket listed. |
| s3:GetObject | Read the objects in the S3 bucket. |
| s3:PutObject | Write objects, such as files, to the S3 bucket. |
| s3: DeleteObject | Delete objects from S3 bucket. Hevo requires this permission to delete the file it creates in your S3 bucket while testing the connection. |
Perform the following steps to create the IAM policy:
-
Log in to the AWS IAM Console.
-
In the left navigation pane, under Access management, click Policies.
-
On the Policies page, click Create policy.

-
On the Specify permissions page, click JSON.

-
In the Policy editor section, paste the following JSON statements:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<your_bucket_name>", "arn:aws:s3:::<your_bucket_name>/*" ] } ] }Note: Replace the placeholder values in the commands above with your own. For example, <your_bucket_name> with s3-destination1.
The JSON statements allow Hevo to access the bucket that you specify while configuring S3 as a Destination and load data into it.
-
At the bottom of the page, click Next.

-
On the Review and create page, specify the Policy name, and at the bottom of the page, click Create policy.
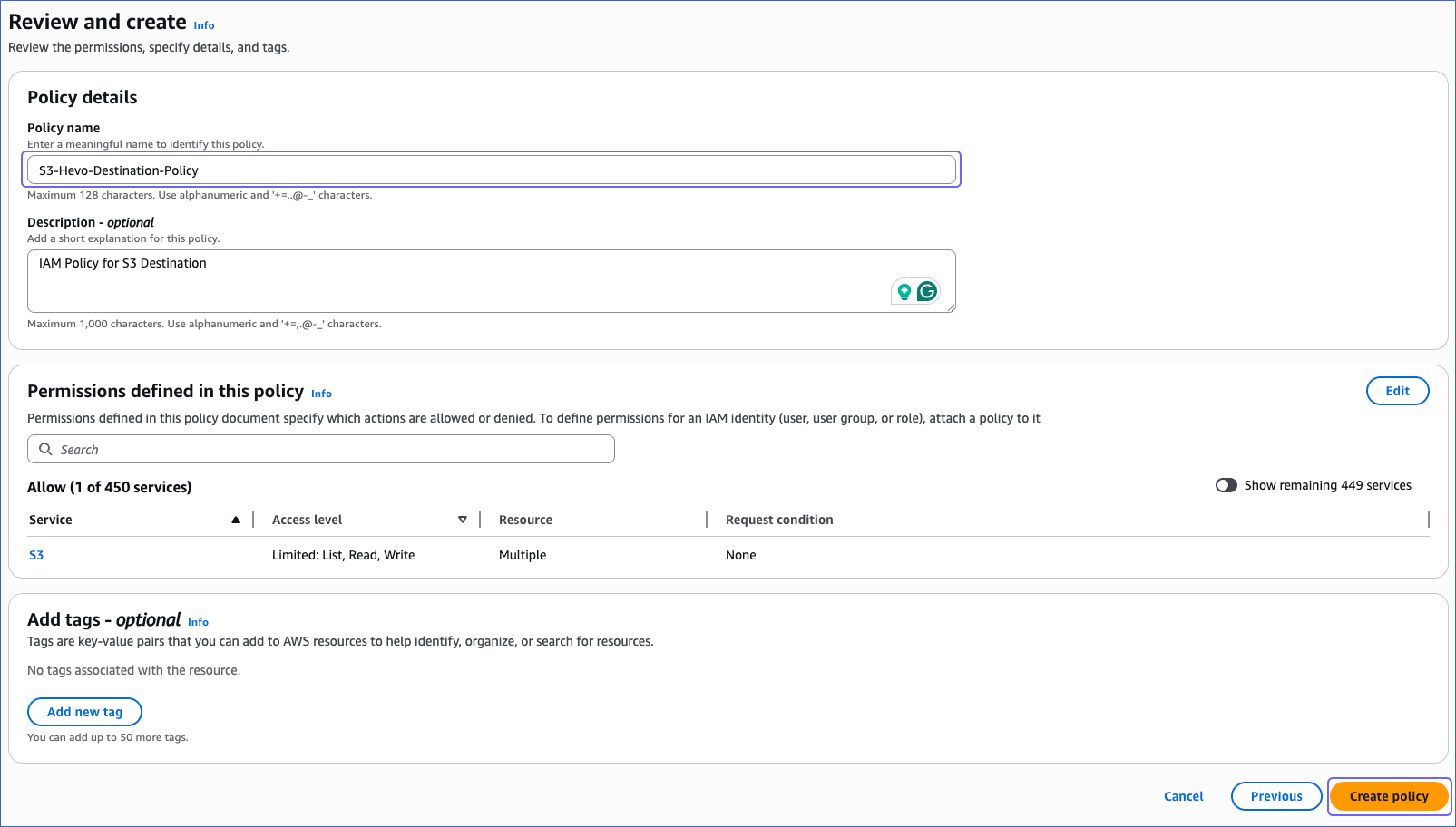
You must assign this policy to the IAM role or the IAM user that you create for Hevo to access your S3 bucket.
Obtain the Amazon S3 Connection Settings
Hevo connects to your Amazon S3 bucket in one of the following ways:
Connection method: Using IAM role
To connect using an IAM role, you need to generate IAM role-based credentials. For this, you need to add an IAM role for Hevo and assign the IAM policy created in Step 2 above to it. You require the Amazon Resource Name (ARN) and external ID from this role to grant Hevo access to your S3 bucket.
1. Create an IAM role and assign the IAM policy
-
Log in to the AWS IAM Console.
-
In the left navigation pane, under Access management, click Roles.
-
On the Roles page, click Create role.

-
In the Select trusted entity section, select AWS account.

-
In the An AWS account section, select Another AWS account, and in the Account ID field, specify Hevo’s Account ID, 393309748692.

-
In the Options section, select the Require external ID check box, specify an External ID of your choice, and click Next.

-
On the Add Permissions page, search and select the policy that you created in Step 2 above, and at the bottom of the page, click Next.

-
On the Name, review, and create page, specify a Role name and a Description.

-
At the bottom of the page, click Create role.
You are redirected to the Roles page.
2. Obtain the ARN and external ID
-
On the Roles page of your IAM console, click the role that you created above.

-
On the <Role name> page, Summary section, click the copy icon below the ARN field and save it securely like any other password.

-
In the Trust relationships tab, copy the external ID corresponding to the sts:ExternalID field. For example, hevo-s3-dest-external-id in the image below.

You can use the ARN and the external ID while configuring S3 as a Destination in Hevo.
Connection method: Using access credentials
To connect using access credentials, you need to add an IAM user for Hevo and assign the policy created in Step 2 above to it. You require the access key and the secret access key generated for this user to grant Hevo access to your S3 bucket.
Note: The secret key is associated with an access key and is visible only once. Therefore, you must save it or download the key file for later use.
1. Create an IAM user and assign the IAM policy
-
Log in to the AWS IAM Console.
-
In the left navigation pane, under Access management, click Users.
-
On the Users page, click Create user.

-
On the Specify user details page, specify the User name, and click Next.

-
On the Set permissions page, Permissions options section, click Attach policies directly.

-
In the Search bar of the Permissions policies section, type the name of the policy you created in Step 2 above.
-
Select the check box next to the policy to associate it with the user, and at the bottom of the page, click Next.

-
At the bottom of the Review and create page, click Create user.
2. Generate the access keys
-
On the Users page of your IAM console, click the user that you created above.

-
On the <User name> page, click the Security credentials tab.

-
In the Access keys section, click Create access key.

-
On the Access key best practices & alternatives page, select Command Line Interface (CLI).

-
At the bottom of the page, select the I understand the above… check box and click Next.
-
(Optional) Specify a description tag for the access key, to help you identify it.
-
Click Create access key.

-
On the Retrieve access keys page, Access key section, click the copy icon in the Access key and Secret access key fields and save the keys securely like any other password. Optionally, click Download .csv file to save the keys on your local machine.
Note: Once you leave this page, you cannot view the secret access key again.

You can use these access keys while configuring S3 as a Destination in Hevo.
Configure Amazon S3 as a Destination
Perform the following steps to configure Amazon S3 as a Destination in Hevo:
-
Click DESTINATIONS in the Navigation Bar.
-
Click + Create Standard Destination in the Destinations List View.
-
On the Add Destination page, select S3.
-
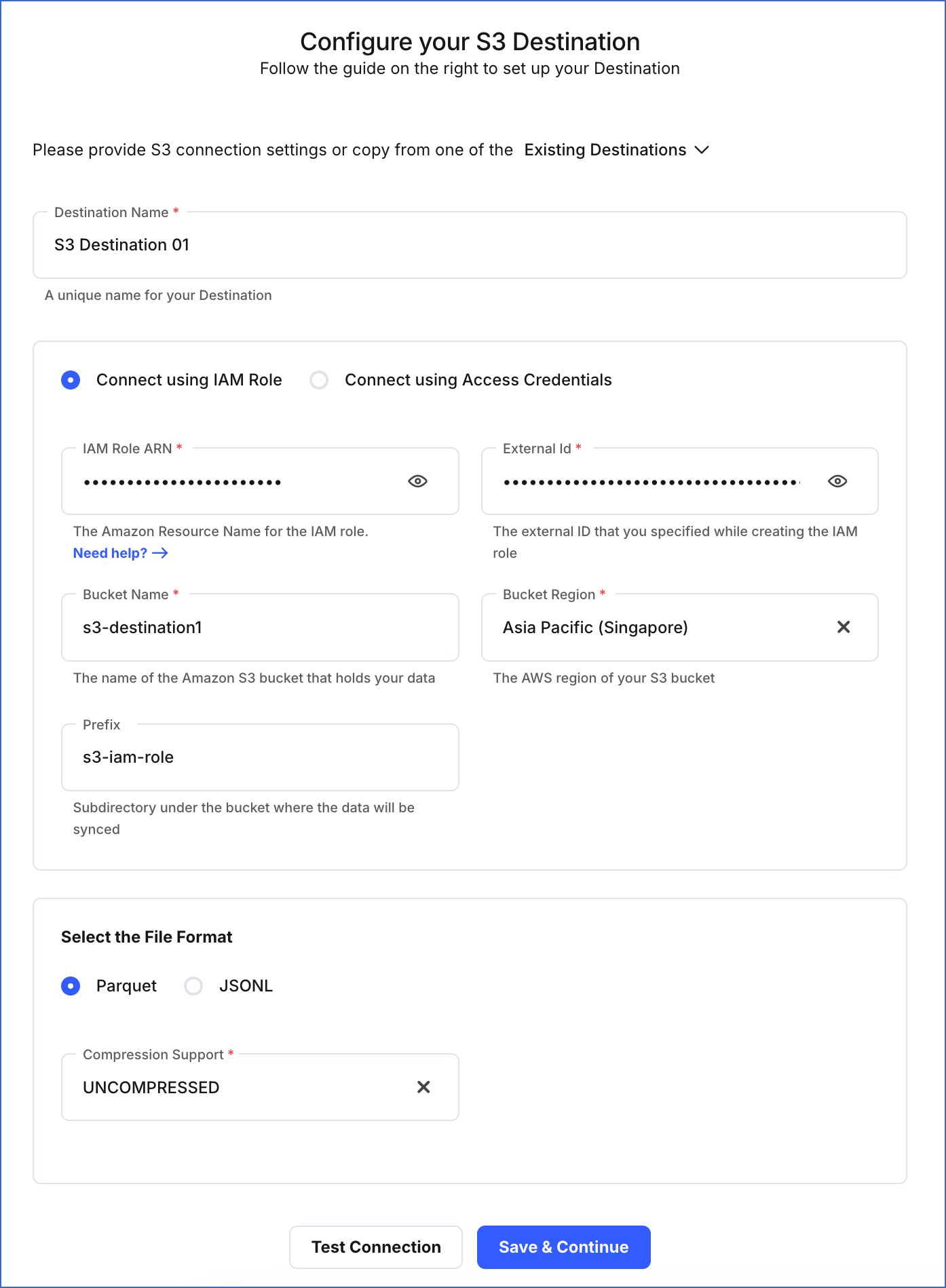
On the Configure your S3 Destination page, specify the following:
-
Destination Name: A unique name for your Destination, not exceeding 255 characters.
-
Select one of the following methods to connect to your Amazon S3 bucket:
-
Connect Using an IAM Role: Connect using the role that you added in the Create an IAM role and assign the IAM policy section above.
-
IAM Role ARN: The globally unique identifier assigned by AWS to the IAM role you created in the section above. For example, arn:aws:iam::102345678922:role/MyRole.
-
External ID: The unique identifier you assigned to the IAM role when you created it in the section above. For example, hevo-s3-dest-external-id.
-
Bucket Name: The name of the bucket where data is to be loaded. For example, s3-destination1.
-
Bucket Region: The AWS region where the S3 bucket is located. For example, Asia Pacific (Singapore).
-
Prefix (Optional): A string added at the beginning of the directory path, to help you organize your data files in the S3 bucket. Refer to Configuring the Pipeline Settings for information on the directory path.
-
-
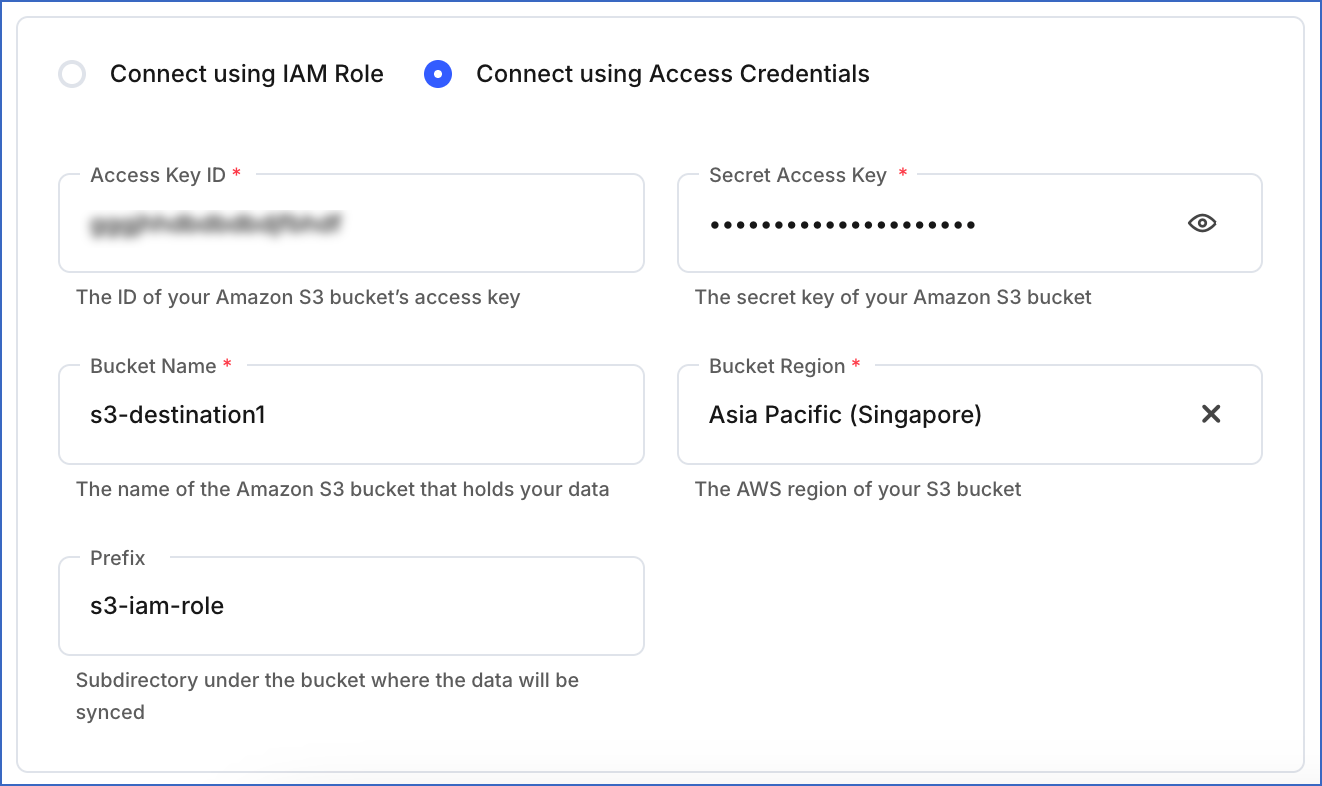
Connect Using Access Credentials: Connect using the IAM user that you added in the Create an IAM user and assign the IAM policy section above.
-
Access Key ID: The publicly shareable unique identifier associated with the access key pair created for your IAM user in the section above. For example, AKIAIOSFODNN7EAAMMBB.
-
Secret Access Key: The cryptographic key associated with the access key ID generated for your IAM user in the section above. For example, wJalrXUtnFEMI/K7MDENG/bPxRfiCYAABBCCDDEE.
-
Bucket Name: The name of the bucket where data is to be loaded. For example, s3-destination1.
-
Bucket Region: The AWS region where the S3 bucket is located. For example, Asia Pacific (Singapore).
-
Prefix (Optional): A string added at the beginning of the directory path, to help you organize your data files in the S3 bucket. Refer to Configuring the Pipeline Settings for information on the directory path.
-
-
-
Select the File Format: The format in which you want to store your data files. Select one of the following:
-
Parquet: In this format, Hevo writes the ingested data to files in a columnar manner, that is data is stored column-wise. Read Apache Parquet to understand this format. Specify the following:
- Compression Support: The algorithm to apply for compressing data before storing it in the S3 bucket. Hevo supports storing data either in an uncompressed form or a compressed form using the SNAPPY algorithm. Default value: UNCOMPRESSED.
-
JSONL: In this format, Hevo writes the ingested data to files as JSON objects, one per line. Read JSON Lines to understand this format. Specify the following:
- Compression Support: The algorithm to apply for compressing data before storing it in the S3 bucket. Hevo supports storing data either in an uncompressed form or a compressed form using GZIP. Default value: UNCOMPRESSED.
-
-
-
Click Test Connection. This button is enabled once all the mandatory fields are specified.
-
Click Save & Continue. This button is enabled once all the mandatory fields are specified.
Configuring the Pipeline Settings
When you create a Pipeline with an S3 Destination, you must specify the directory path, or folder structure. Hevo loads the data files into your S3 bucket at the specified location.
This is the default directory path:
${PIPELINE_NAME}/${OBJECT_NAME}/${DATE}/${JOB_ID}
Hevo creates the data files in this path by replacing these parameters as follows:
-
${PIPELINE_NAME}: The name of your Pipeline that uses the configured S3 bucket as a Destination.
-
${OBJECT_NAME}: The name of the Source object from which data was ingested.
-
${DATE}: The date when the data was loaded to your S3 bucket.
-
${JOB_ID}: The ID of the job in which the data ingestion task ran.
If you specify a prefix while configuring your S3 Destination, it is appended at the beginning of the directory path and your data files are created in that location.
Note: ${PIPELINE_NAME} and ${OBJECT_NAME} are mandatory parameters and your directory path must contain these two.
You can also specify a directory path to organize your data files into folders created using time-based parameters. For this, append one or more of the following parameters after ${PIPELINE_NAME}/${OBJECT_NAME}:
-
${YEAR}: The year when the data load task ran.
-
${MONTH}: The month when the data load task ran.
-
${DAY}: The day when the data load task ran.
-
${HOUR}: The hour of the day when the data load task ran.
For example, if you want to organize your Source data in the S3 bucket based on the day and hour, you should specify the path as ${PIPELINE_NAME}/${OBJECT_NAME}/${DAY}/${HOUR}.
Limitations
-
Your S3 bucket must be created in one of the AWS regions supported by Hevo.
-
At this time, Hevo supports loading data only in the Append Rows on Update mode.