Best Practices for Creating Database Pipelines
Database Pipelines can involve reading and writing a huge amount of data, and this can lead to high data storage costs and slower replication of the relevant updates. Following best practices can help you select the most suitable Pipeline configurations to minimize cost and maximize efficiency and optimize the loading of data to the Destination.
Ingestion Best Practices
-
Select the Full Load query mode only if Change Data Capture (CDC) mode is not available for the Source, or if there is no column with incrementing values that can be used to identify the changed data.

Advantage: Avoiding the Full Load mode is recommended because this mode fetches the entire data from the Source each time. This can increase the cost of running the deduplication queries and reduce the efficiency of the ingestion process. It also consumes resources that can be used for other jobs.
-
If you are using a query mode such as Unique Incrementing Append Only, Delta-Timestamp, or CDC, you should have indexes on the objects that are selected in the Configure Objects page. Avoid the Full Load query mode if the data is not indexed. The Full Load mode should be your last alternative.
Advantage: Queries on indexed data consume less time compared to non-indexed data.
-
Disable the Include New Tables in the Pipeline option while configuring the Source settings during Pipeline creation. Instead, modify the Pipeline later to add the relevant new tables.
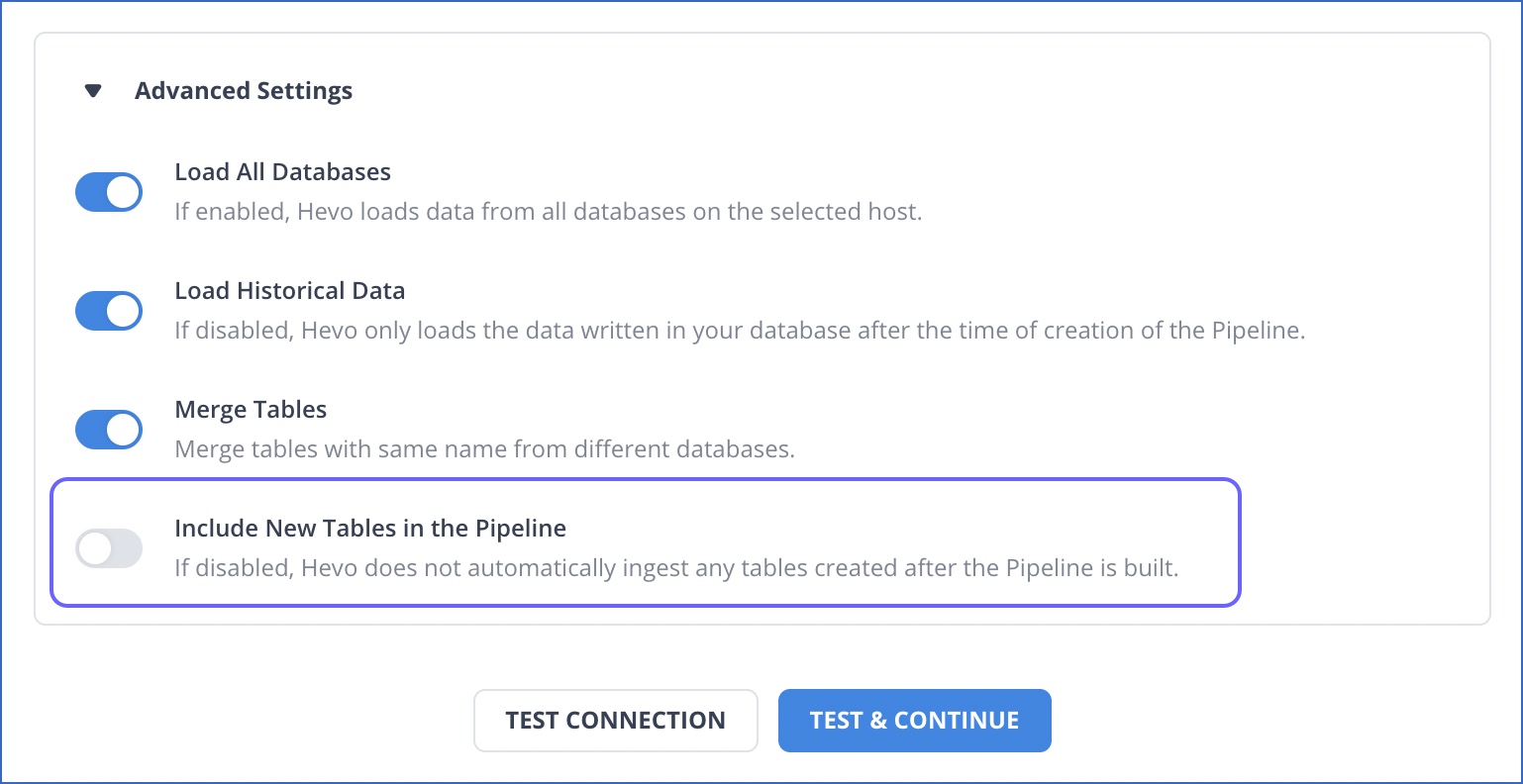
Advantage: This allows you to have more control on which new objects must get loaded via the Pipeline. You can save on storage costs and the time for running unnecessary queries, which would otherwise be used to ingest and load the new objects. Further, if you have enabled Auto-Mapping, keeping this option enabled could also result in creation of new tables in the Destination.
-
You can enable this option for an existing Pipeline:
-
In the Pipeline Overview page, click Settings (
 ) and then click Edit (
) and then click Edit ( ).
).
-
In the Edit Source Pipeline connection settings, click Advanced Settings.
-
Enable the toggle option for Include New Tables in the Pipeline. Default value: Enabled.

-
Click TEST & SAVE to update the Pipeline configuration settings.
-
-
Skip the objects you do not need while configuring the Source.
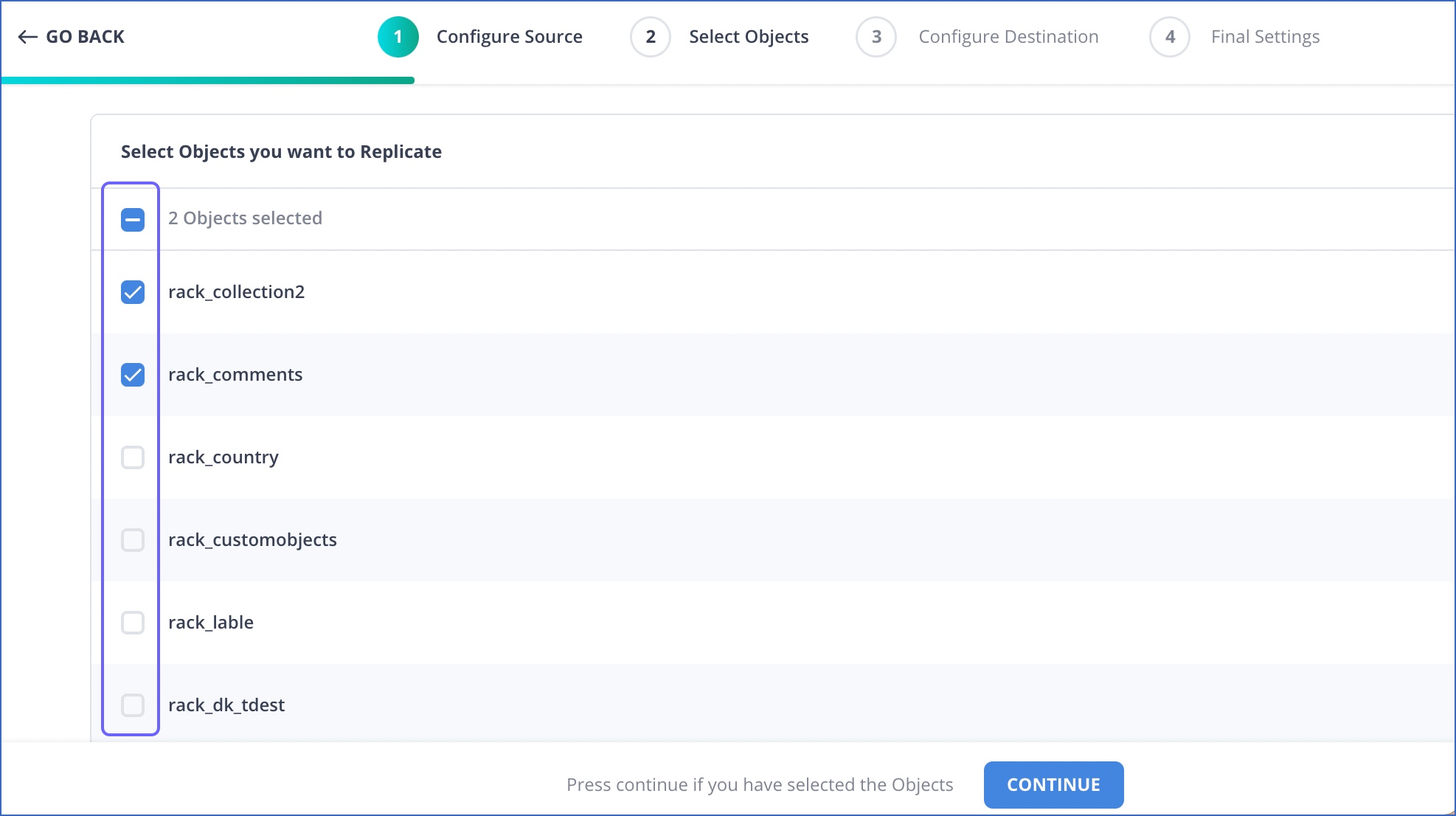
Advantage: By avoiding the loading of Events you may not eventually need, you can save your Events quota. The lesser the number of Events competing for resources, the shorter the ingestion queues would be.
-
If you have enabled the Load Historical Data option in Source configuration, select any incremental query mode such as Change Data Capture (based on ID and time).
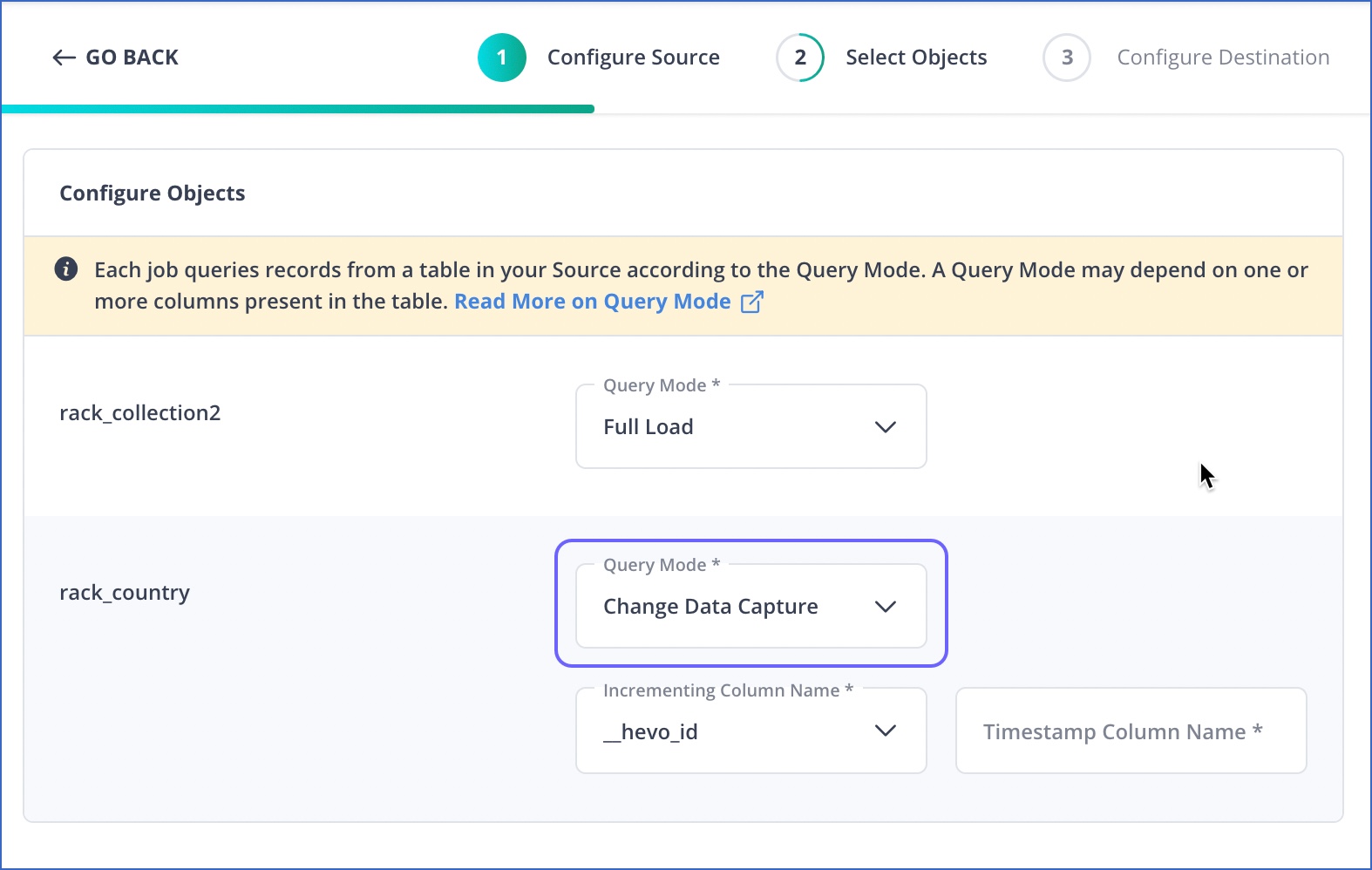
Advantage: The incremental query modes provide Hevo an incrementing ID to use for fetching the historical data in lots, if it exceeds 5 Million rows or if it takes beyond 1 hour to load. In the Full Load mode, on the other hand, the Pipeline would keep fetching the same data in each run.
-
In case there are no indices created on the time columns (for CDC), prefer using indexed incremental columns.
Advantage: In the case of large tables, the queries on indexed columns are less expensive.
-
For log-based Pipelines, set up the recommended 72-hr retention period for logs.
Advantage: This reduces the risk of Events getting discarded from the log before they are read by the Pipeline. Read the sections relevant to your Source variant for more information.
-
If you are looking for just a denormalized view, then, instead of ingesting all the objects and subsequently creating a view in the Destination, use the Custom SQL Pipeline mode and fetch the view.
Advantage: The cost benefit of first loading the entire data and then using Transformations to filter it and create the required view may not be worth the effort this requires.
-
Connect a replica instead of the master database instance.

Read the Create a Read Replica section for your Source variant for steps to do this. For example, Create a Read Replica section in the case of Azure MySQL.
Advantage: If you read from and write to the
masterdatabase, extra resources are used for comparing the data. Instead, you can read from themasterand write to thereplicaso that resources are distributed. Thereplicasubsequently reconciles the data with themasterinstance. This increases the cost but improves efficiency and reduces redundancy.
Replication Best Practices
-
If the incoming data is Append-only, consider enabling the Append Rows on Update setting.
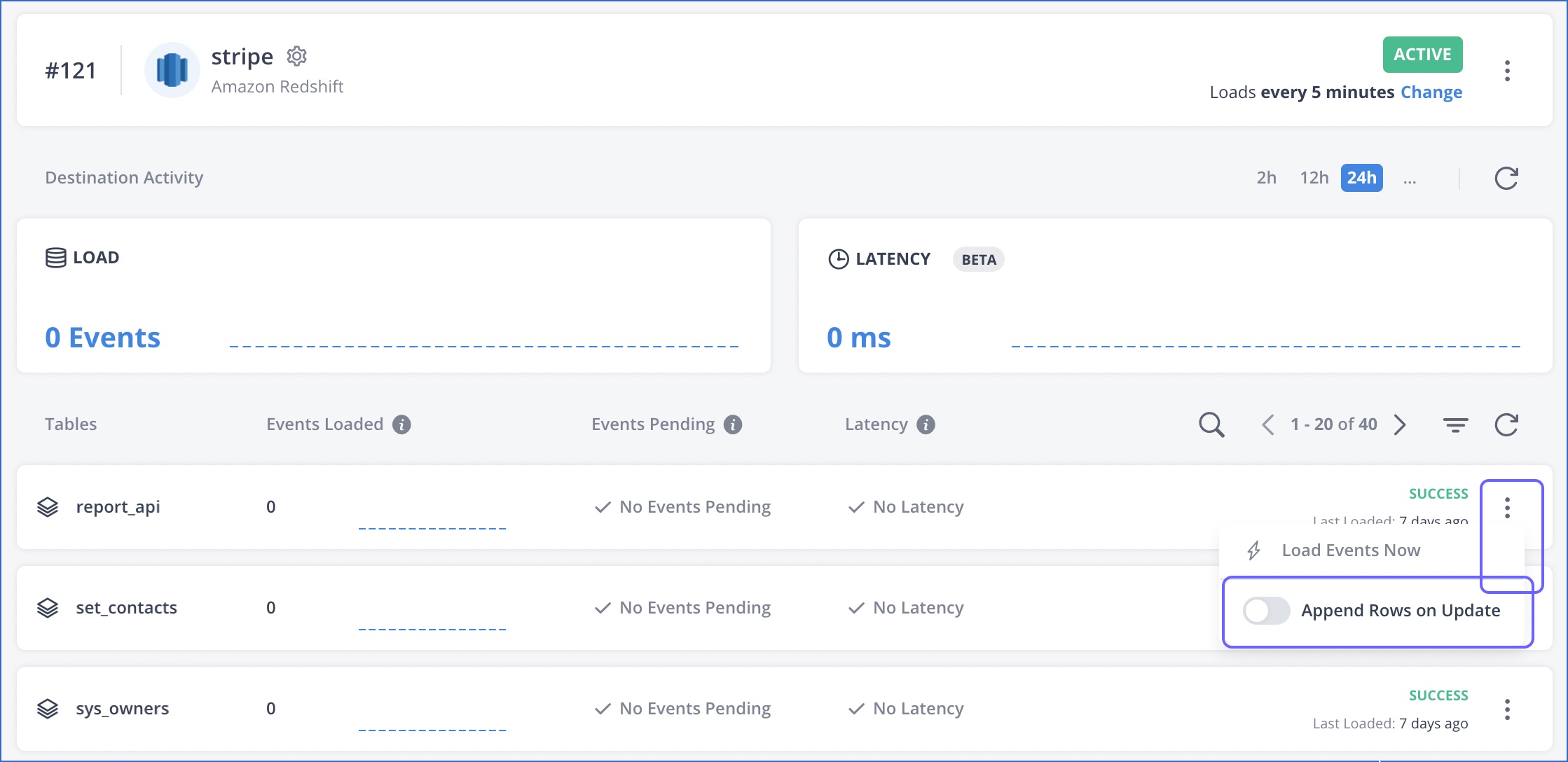
Advantage: With this option enabled, Hevo does not attempt to deduplicate the incoming data against what already exists in the table, thus reducing warehouse costs.
-
In case the Destination tables have grown large, have a lower load frequency (larger time separation between consecutive load runs).

Advantage: Less frequent loading incurs less cost on the warehouses.
-
If you want to optimize the tables for your analytical queries, create the tables manually, (Auto Mapping off).
Advantage: This allows you to select the appropriate sort or partition keys. Hevo does not automatically add sort or partition keys to the tables.
-
Exclude the columns that are not required via Transformations or Schema Mapper.
Advantage: Writing very wide tables is expensive and often fails. Therefore, select only the columns that you need to write to.
-
(Redshift specific) Use the JSON split strategy during ingestion only when you really need it. Instead, you can extract the JSON in Transformations and create only selected new Events.
Advantage: This helps you control the table size and number. The number of tables and columns can grow drastically depending on the JSON data from the Source.