How can I make sure that each record is loaded only once?
To ensure that each record is loaded only once, you can take some actions prior to and post-Pipeline creation:
- Pre-Pipeline creation:
-
Create the Pipeline with Auto Mapping disabled. Manually map the Event Type (Source object) and define one of the fields as the primary key. This field must have unique and non-null values. Finally, enable Auto Mapping for the Event Type.
-
Disable the Append Rows on Update option for the table in the Destination Overview page.

Read How do I enable or disable the deduplication of records in my Destination tables?
Note: This feature is available only for Amazon Redshift, Google BigQuery, and Snowflake Destinations.
-
Post-Pipeline creation
-
Disable Auto Mapping for the Event Type from the Schema Mapper.

-
Click the Kebab menu icon next to the Destination Table name and click Drop Table.

-
Click CREATE TABLE & MAP to create a new Destination table.

-
Set a field as the primary key by selecting the Primary Key check box for it.
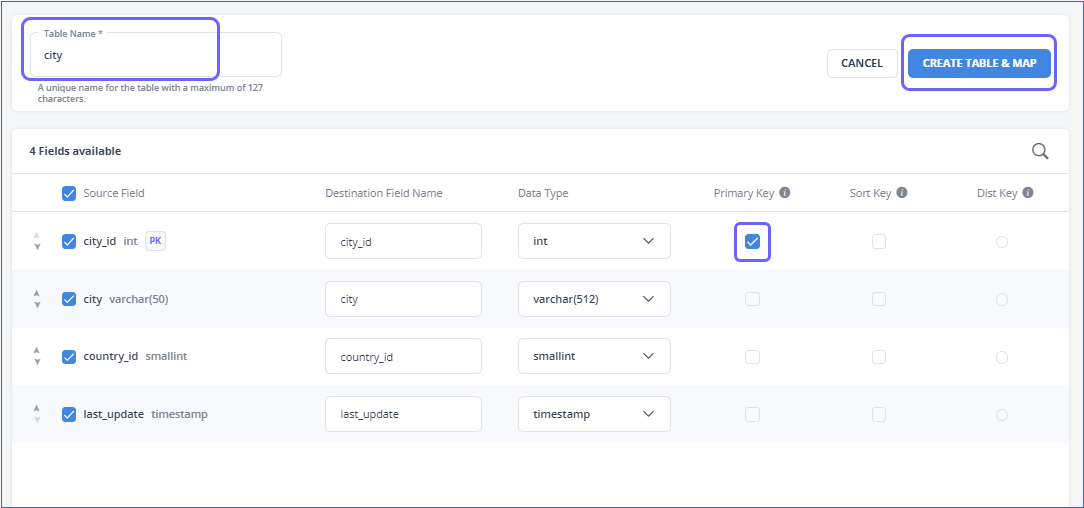
-
Specify the Destination Table Name and click CREATE TABLE & MAP.
The data is replicated to the new Destination table as per the Pipeline schedule, using the defined primary keys to ensure no duplicate Events are created.