Data Pipelines
Organizations are aspiring to become data driven. Intuitive decision-making is getting replaced by fact-based decision-making that is backed by data. Often, enterprises find it difficult to implement this data-driven decision-making as most of the workforce performing this task could be non-technical. Integrating data to make it accessible for analytics is a highly technical process. This is what data pipelines enable organizations to do; make data analysis easier for business analysts.
Pipelines in Hevo
A data pipeline, or Pipeline in Hevo is a no-code data processing framework that loads data from any Source such as a database, SaaS application, or file into a Destination database or data warehouse. For example, you may load data from your Facebook Ads account to a Google BigQuery data warehouse for analysis.
With just a few clicks you can have analysis-ready data at your finger tip, without any data loss. You can even view samples of incoming data in real-time as it loads from your Source into your Destination.
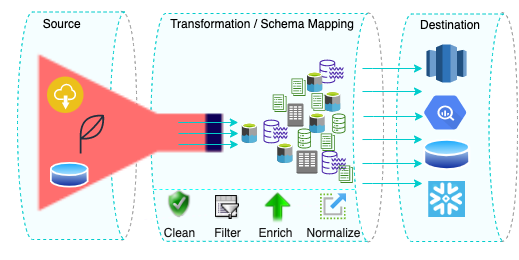
Pipeline Components
The following form the key components of a Pipeline:
-
Source: A Source is a database, an API endpoint or a file storage that holds the data that you want to analyze. Hevo integrates with over 100+ Sources. Read Sources.
-
Transformations: Python or UI-based Transformations are useful when you want to clean, enrich, or transform your data before loading it to your Destination. Read Transformations.
-
Schema Mapper: The Schema Mapper lets you map your Source schemas to tables in your Destination automatically or manually. Read Schema Mapper.
-
Destination: The Destination is the data warehouse or database where the data collected from Sources is stored. Read Destinations.
In a Pipeline, one Source maps to one Destination only. However, the same database or data warehouse may be configured as a Destination for multiple Sources.
Benefits of Creating Pipelines Using Hevo
Following are some of the benefits of creating Pipelines using Hevo:
-
Near Real-Time Data Transfer: Hevo provides real-time data migration, so you can perform data analysis anytime as per your business need.
-
100% Complete and Accurate Data Transfer: Your Hevo Pipeline ensures reliable data transfer with zero data loss.
-
Scalable Infrastructure: Seamless integrations with Sources can help you scale your data infrastructure as per your business need.
-
Live Monitoring: Options to view the data and its movement along different stages of the Pipeline allows you to monitor the progress of your data replication. Read Data Ingestion Statuses and Viewing Pipeline Progress. You can also control the number of Events your Pipelines load per day and be alerted whenever this limit is exceeded. Read Data Spike Alerts.
-
Connectors: Hevo supports integration with various warehouses including Google BigQuery, Amazon Redshift, and Snowflake, Amazon S3 data lakes, and MySQL, MongoDB, TokuDB, DynamoDB, PostgreSQL databases to name a few. Read Sources.
-
Transformations: Pipelines created in Hevo provides preload Transformations. You can also use the Python or the drag and drop Transformations like Date and Control Functions, JSON and Event Manipulation to perform your own Transformations. These can be configured and tested before being put to use. Read Transformations.
-
Schema Management: Pipelines created in Hevo take away the tedious task of mapping and managing the Destination schema. The Auto Mapping feature automatically detects the schema of your incoming data and maps it to the Destination schema. You also have the option to do this manually.