Amazon Simple Storage Service (S3) is a durable, efficient, secure, and scalable cloud storage service provided by Amazon Web Services (AWS) that can be accessed from anywhere. S3 uses the concept of buckets to store data such as images, videos, and documents, in multiple formats, organize that data, and retrieve it at any time from the cloud. It also provides you access control, versioning, and integration with other AWS services.
Hevo supports the replication of S3 data in the AVRO, CSV, JSON, TSV, and XML file formats. While ingesting data, Hevo automatically unzips any Gzipped files. Further, if any file is updated in the Source, Hevo re-ingests its entire contents as it is not possible to identify individual changes.
Accessing data in S3 buckets
In S3, access is defined through IAM policies and an IAM user. You can create an IAM user and assign the IAM policy to it to define what data Hevo can access.
Prerequisites
-
An active AWS account and an S3 bucket from which data is to be ingested exist.
-
You are logged as an IAM user with permission to:
-
The access credentials are available to authenticate Hevo on your AWS account.
-
Your S3 bucket policy provides the Hevo account ID access to the bucket and the objects within it.
Create an IAM Policy
Create an IAM policy with the ListBucket and GetObject permissions. These permissions are required for Hevo to access data from your S3 bucket.
To do this:
-
Log in to the AWS IAM Console.
-
In the left navigation pane, under Access management, click Policies.
-
In the Policies page, click Create policy.

-
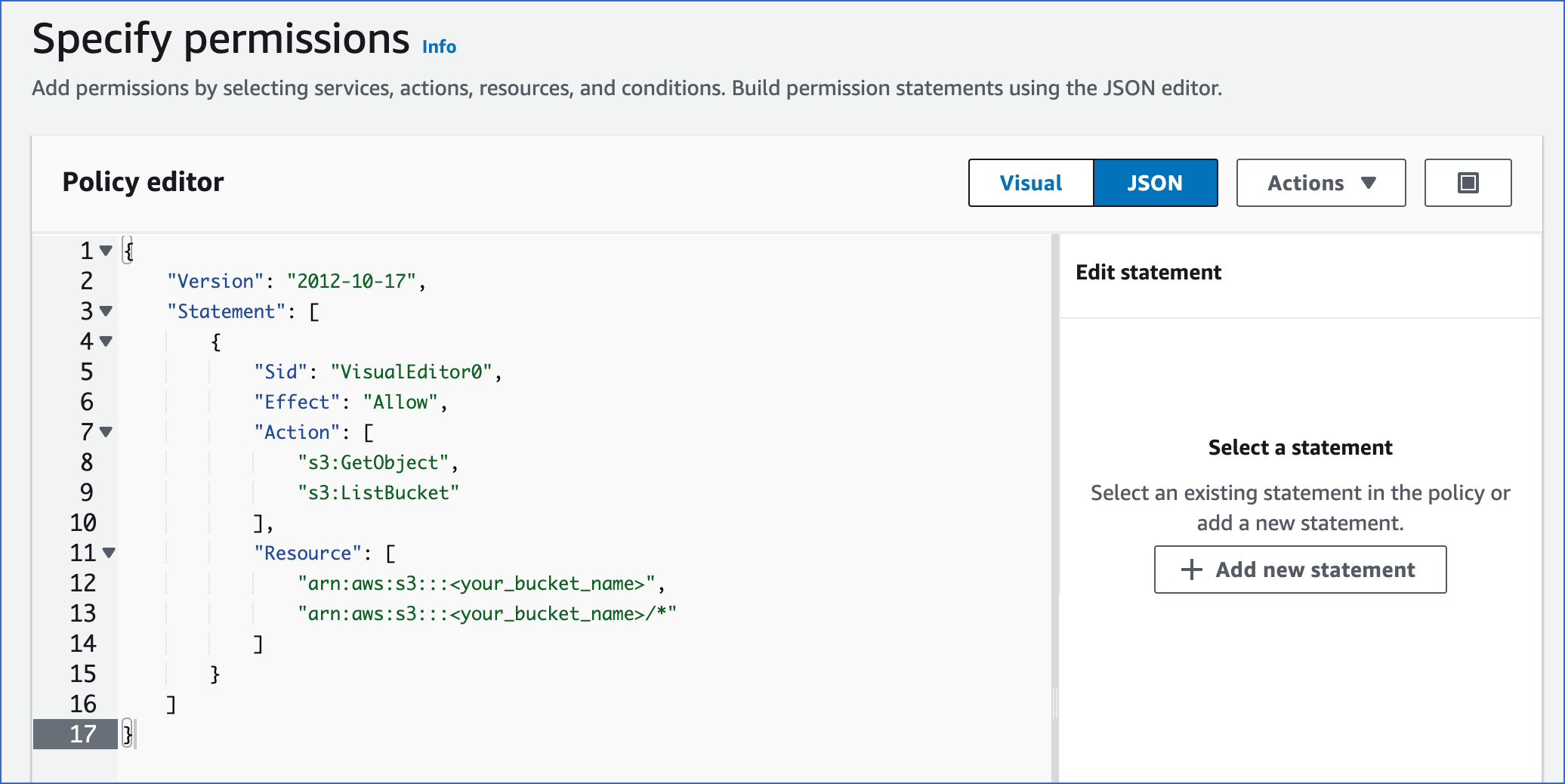
In the Specify permissions page, click JSON, and in the Policy editor section, paste the following JSON statements:

Note: Replace the placeholder values in the commands below with your own. For example, <your_bucket_name> with Hevo-S3-bucket.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<your_bucket_name>", "arn:aws:s3:::<your_bucket_name>/*" ] } ] }The JSON statements allow Hevo to access and ingest data from the bucket name you specify.
-
At the bottom of the page, click Next.

-
In the Review and create page, specify the Policy name, and at the bottom of the page, click Create policy.
Obtain Amazon S3 Credentials
You must generate access credentials to access and ingest your S3 data.
Your access credentials include the access key and the secret access key. To generate these, you need to create an IAM user for Hevo and assign the policy you created in Step 1 above to it.
Note: The secret key is associated with an access key and is visible only once. Therefore, you must make sure to save the details or download the key file for later use.
1. Create an IAM user and assign the IAM policy
-
Log in to the AWS IAM Console.
-
In the left navigation pane, under Access management, click Users.
-
In the Users page, click Create user.
-
In the Specify user details page, specify the User name and click Next.

-
In the Set permissions page, Permissions options section, click Attach policies directly.
-
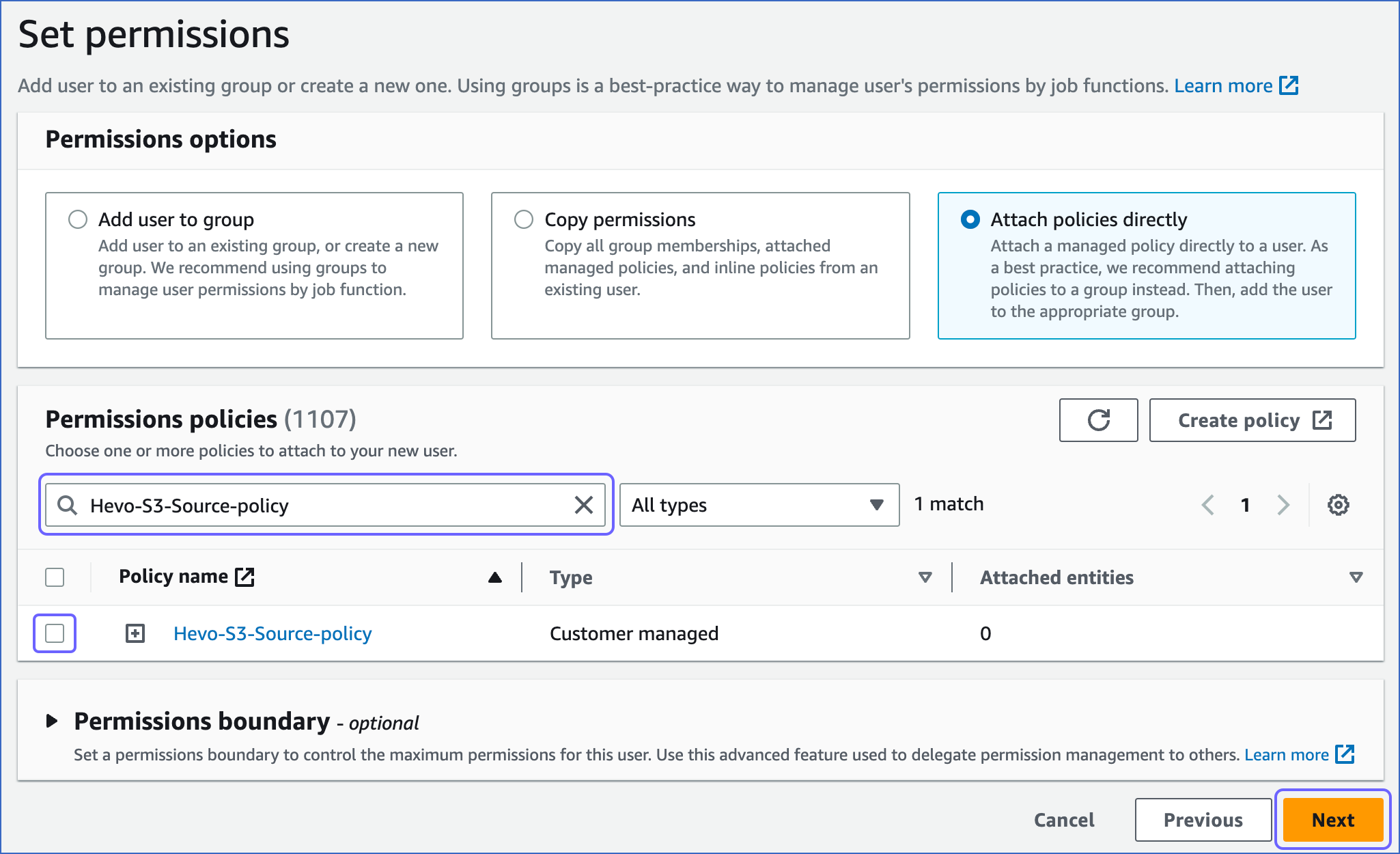
In the Permissions policies section, search and select the check box corresponding to the policy that you created in Step 1 above and at the bottom of the page, click Next.
-
At the bottom of the Review and create page, click Create user.
2. Generate the access keys
-
In the Users page of your IAM console, click the user that you created above.

-
In the <User name> page, select the Security credentials tab.
-
In the Access keys section, click Create access key.

-
In the Access key best practices & alternatives page, select Command Line Interface (CLI).

-
At the bottom of the page, select the I understand the above…. check box and click Next.

-
(Optional) Specify a description for the access key.
-
Click Create access key.

-
In the Retrieve access keys page, Access key section, click the copy icon in the Access key and Secret access key fields and save the keys securely like any other password.
Optionally, click Download .csv file to save the keys on your local machine.
Note: Once you leave this page, you cannot view these keys again.

Use these keys while configuring your Pipeline.
Create S3 Bucket Policy
Create a policy for your S3 bucket and Hevo access to the bucket and its objects. The Principal key in the policy provides this access to the Hevo account ID.
Note: The following steps must be performed by a Root user or a user with administrative access. In AWS, permissions and roles are managed through the IAM page.
-
Log in to your AWS account and open the Amazon S3 console.
-
In the left navigation pane of your Amazon S3 dashboard, click Buckets.
-
In the General purpose buckets page, click the S3 bucket you want to configure as your Source.
-
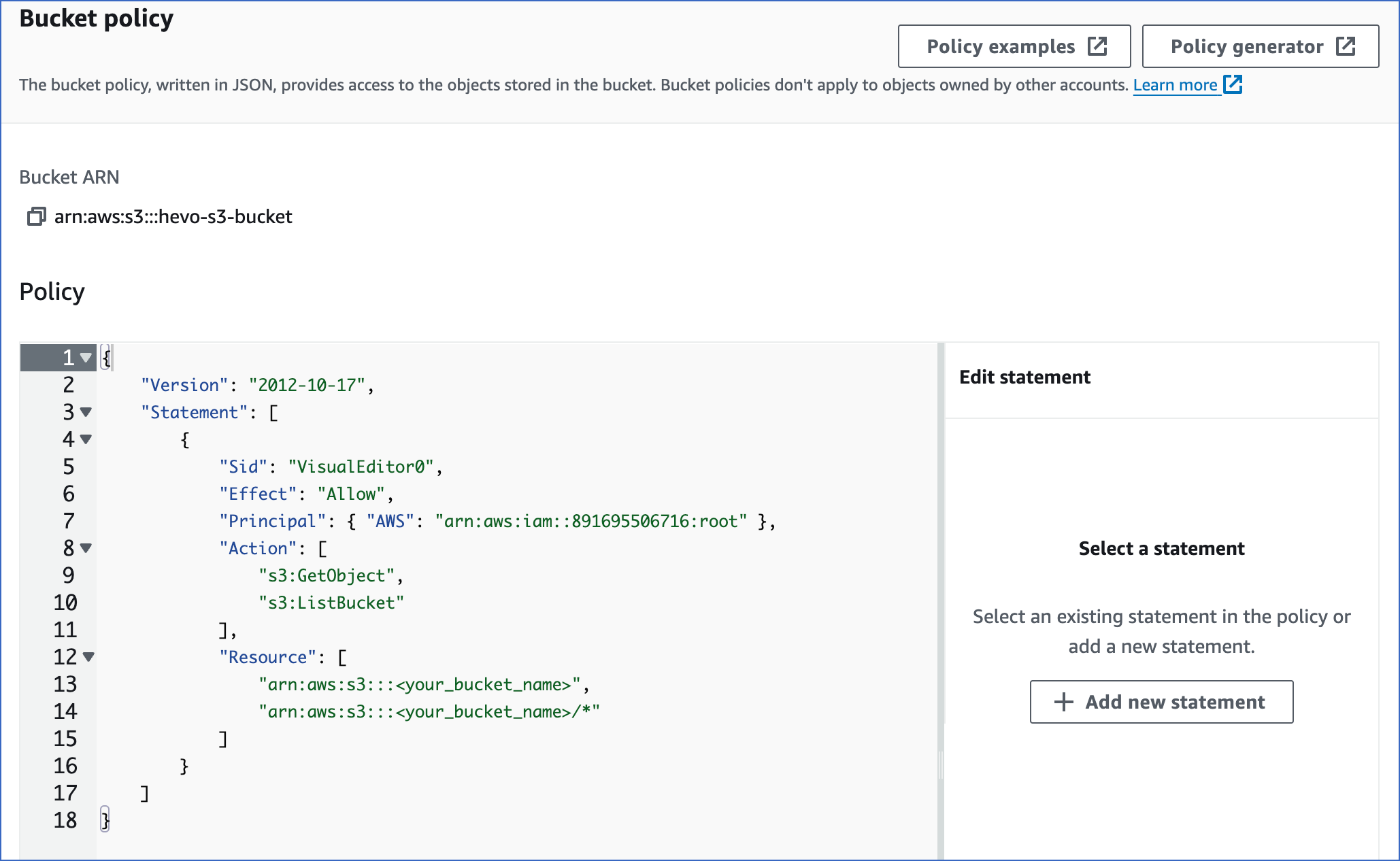
In the <Bucket name> page, under the Permissions tab, navigate to the Bucket policy section and click Edit.

-
In the Policy editor section, paste the following JSON statements:
Note: Replace the placeholder values in the commands below with your own. For example, <your_bucket_name> with hevo-s3-bucket.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::891695506716:root" }, "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<your_bucket_name>", "arn:aws:s3:::<your_bucket_name>/*" ] } ] }The JSON statements allow the Hevo account ID access to the specified bucket and its objects.
-
At the bottom of the page, click Save changes.

Configure Amazon S3 as a Source
Perform the following steps to configure S3 as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE ENTERPRISE PIPELINE in the Enterprise Engine - Pipeline List View.
-
On the Source Configuration page, select AWS S3.
-
In the screen that appears, specify the following:

-
Pipeline Name: A unique name for the Pipeline, not exceeding 50 characters. For example, Hevo S3 Source.
-
Access type: The setup method used to allow Hevo to access data from your S3 account. Hevo uses the Key Based method.
-
Access key ID: The access key that you retrieved above.
-
Secret Access key: The secret access key that you retrieved above.
-
Bucket Name: The name of the bucket from which you want to ingest data.
-
Region: The AWS region where the bucket is located.
-
-
Click TEST & CONTINUE.
Object Configuration
Once you have specified the Source, Destination, and Pipeline configurations, perform the following steps to configure the object settings:
-
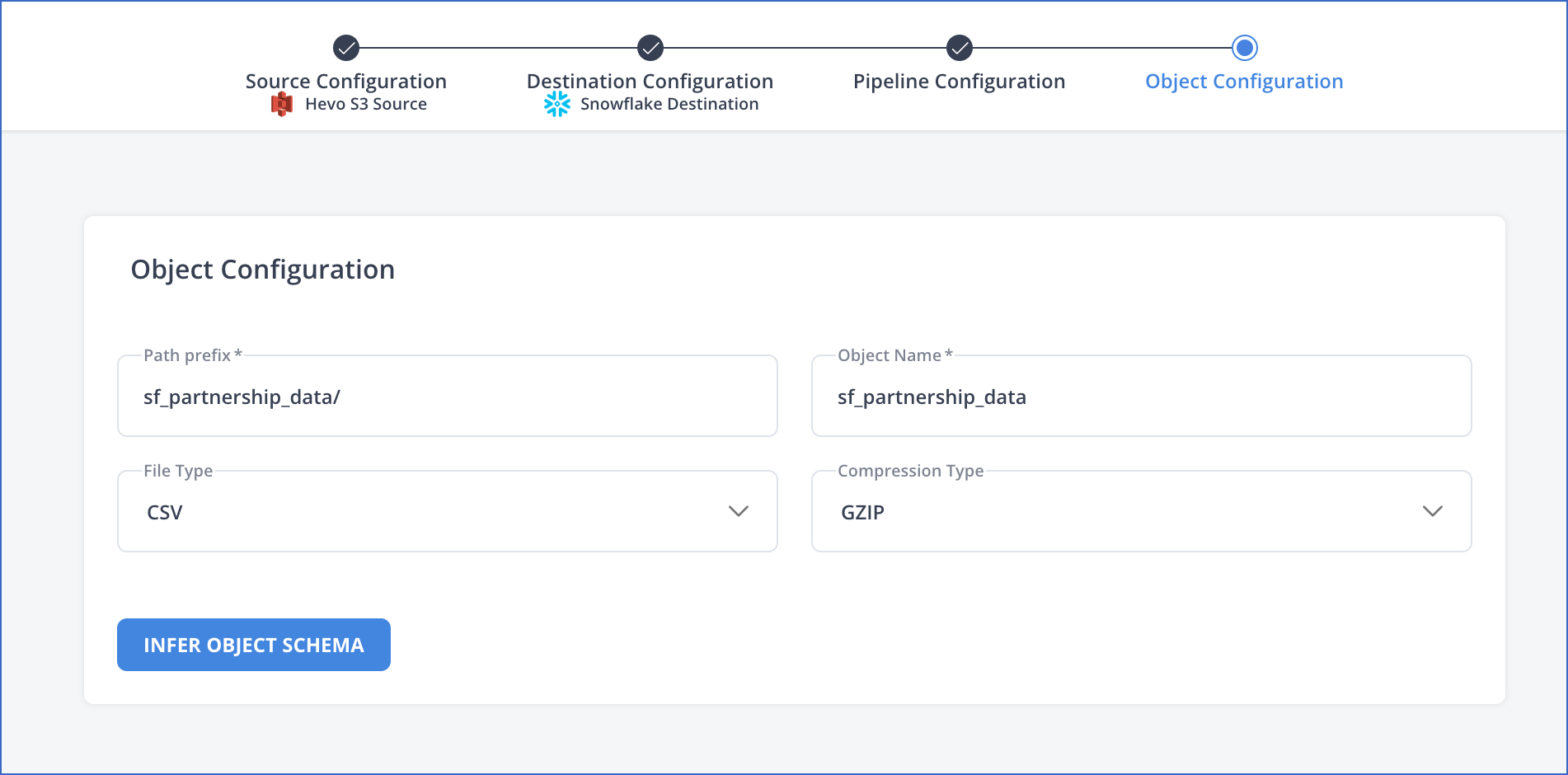
In the Object Configuration page, specify the following:
-
Path prefix: The prefix of the path for the directory that contains your data. Provide the value as / if you want the system to read from the root of the bucket and ingest all the data in the bucket. To ingest data only from a specific folder or subfolder within the bucket, specify the folder path in the following format: <folder name>/<subfolder name>/.
Note: Hevo ingests only files with a consistent schema. This means the files must have similar structure, columns, column data types, and so on. Files that do not meet this criteria will be ignored.
-
File Type: The format of the data files in the specified path. Hevo supports CSV and JSON.
Note: You can select only one file format at a time. If some of your Source data is in a different format, you can export the data to the selected format and then ingest the files.
-
Compression Type: The method of compression of the files in the specified path. Hevo supports the GZIP compression type only. If you select None, Hevo does not ingest any compressed file present in the selected folders.
-
Object Name: The name of the Destination table to which you want to load the data.
-
-
Click INFER OBJECT SCHEMA to retrieve the schema of the Source object(s).
-
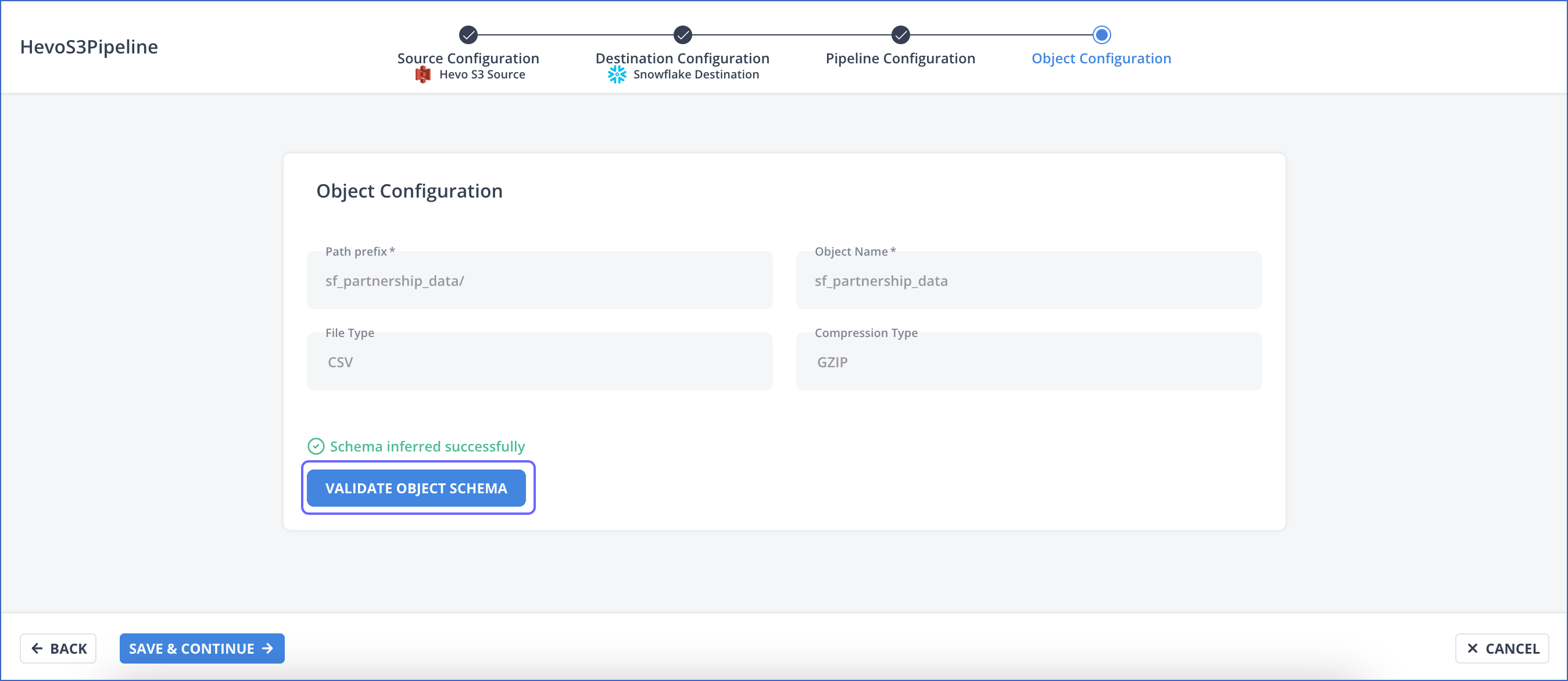
Click VALIDATE OBJECT SCHEMA to view the list of fields in the Source object(s) and edit them, if required.
-
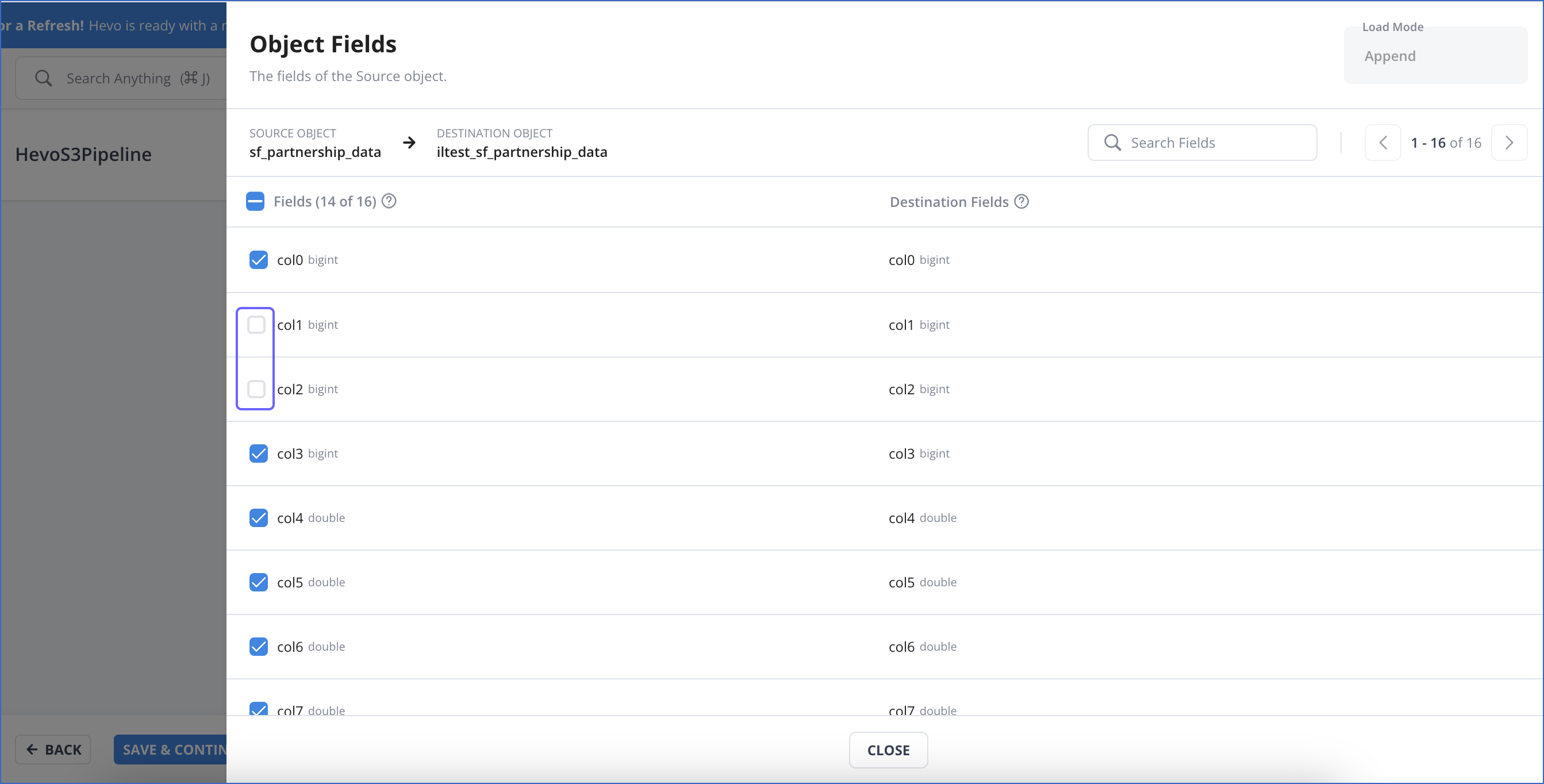
The Object Fields page displays the list of Source object fields and their mapped Destination fields. Deselect the check box next to a field to exclude it for ingestion and loading.
-
In the Object Configuration page, click SAVE & CONTINUE.