On-Demand Syncing Data in Edge Pipelines
Edge Pipelines sync data ingested from your Source with the Destination according to the Pipeline sync schedule. However, in some cases, you may want the Pipeline to sync data outside of the schedule, such as the following:
-
Immediate Deployment Needs: Load data from a newly created Pipeline into the Destination at the earliest for analysis.
-
Resolution of Failures: Replicate data immediately after changing the Pipeline configuration to resolve job failures, rather than waiting for the next scheduled run.
-
Recovery from Downtime: Trigger scheduled jobs that failed because the Source, the Destination, or both were unavailable due to an outage or planned maintenance.
-
Troubleshooting and Validation: Replicate data immediately to resolve mismatches between the Source and Destination data, assisting in troubleshooting.
-
Schema Updates: Load data from new objects included in the Pipeline into the Destination without waiting for the next run.
-
Workflow Dependencies: Trigger the Pipeline to run only after an upstream process, such as a database backup or another ETL job, completes to maintain data integrity.
To handle such scenarios, Hevo allows you to sync or resync data for your Pipeline on demand. This can be done using one of the following methods:
On-Demand Syncing via Hevo UI
You can bypass the scheduler from the UI to trigger immediate data ingestion using:
-
Sync Now: Fetches only incremental updates, which include new or modified records, since the last successful sync.
-
Resync Pipeline: Restarts the historical load for all active objects in the Pipeline. Use this option if you need to refresh the entire dataset to ensure data integrity or to recover from significant data mismatches.
Syncing via External Orchestration
You can trigger your Pipeline using external tools when it depends on the completion of upstream tasks. This approach provides the following capabilities:
-
API-Driven Triggers: These use Hevo Public APIs to initiate a sync, allowing you to integrate Hevo into broader workflows managed by orchestrators such as Apache Airflow.
-
Event-Driven Workflows: These trigger a sync in response to specific events, such as the completion of the Source database backup, ensuring that the Pipeline runs only when the Source data is verified and ready, maintaining consistency across your data processes.
Read Edge API documentation for information on the external APIs and Using Edge Pipelines with Airflow for an end-to-end Airflow example.
Sync Now
The Sync Now action starts a job to sync incremental data from your Source with the Destination. To start this job for your Pipeline, do the following:
-
In the Pipelines List View, click the Edge tab and then click the Pipeline whose data you want to sync.
-
In the Pipeline Summary bar, click the Kebab menu icon (
 ) and click Sync Now.
) and click Sync Now.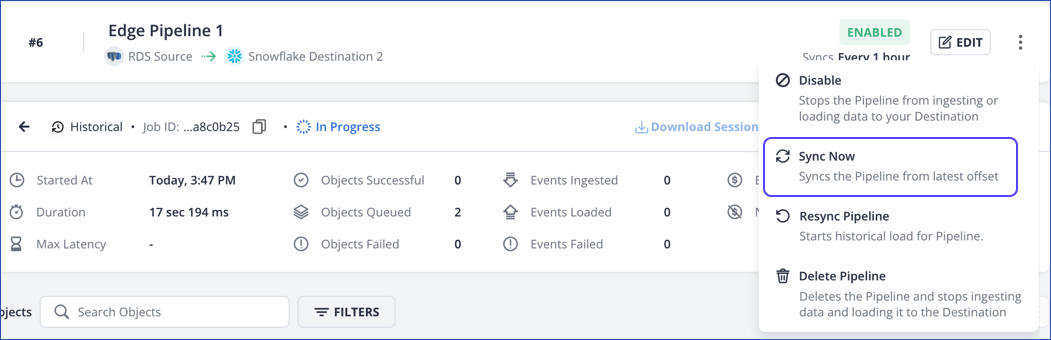
-
In the pop-up dialog, click SYNC NOW.

After you click SYNC NOW, Hevo performs the following actions on your Edge Pipeline:
-
Check if any job is in progress and prompt to cancel the active job. You can then choose to cancel the active job and start a new sync.
-
Start the incremental data sync from the last successful offset for all the objects included in the Pipeline.
-
Start the historical data sync for newly included objects in the Pipeline.
Resync Pipeline
The Resync Pipeline action allows you to restart the historical load for all the active objects in your Pipeline. Resyncing a Pipeline re-ingests historical data from the Source objects. However, the data existing in the corresponding Destination tables is only updated if changes are detected in the re-ingested data. Hevo also evolves the schemas of the Destination tables if any changes are detected in the mapping. Now, if any of the objects are blocked due to incompatible schema evolution, you can choose to drop the Destination tables during the resync operation for all the active objects in your Pipeline. In this case, Hevo drops and re-creates the Destination tables for all the active objects. Data from the Source objects is re-ingested and loaded into the newly created Destination tables.
Note: You can only resync a Pipeline that is Enabled.
Perform the following steps to resync your Edge Pipeline:
-
In the Pipelines List View, click the Edge tab and then click the Pipeline that you want to resync.
-
In the Pipeline Summary bar, click the Kebab menu icon (
) and click Resync Pipeline.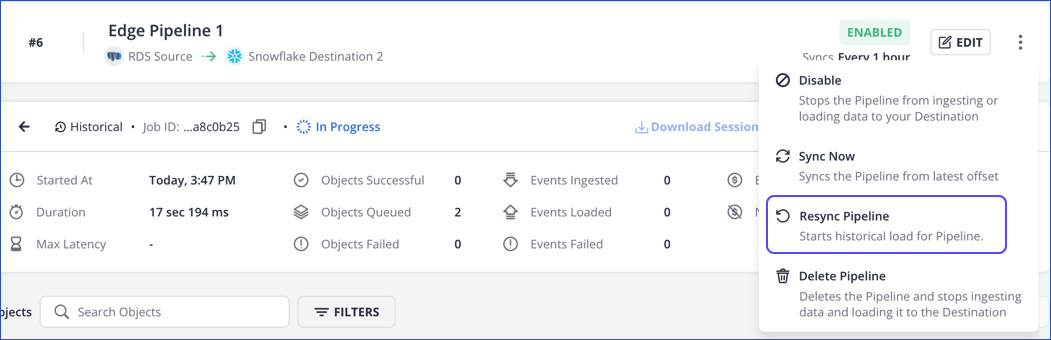
-
In the Resync Pipeline pop-up window, do the following:
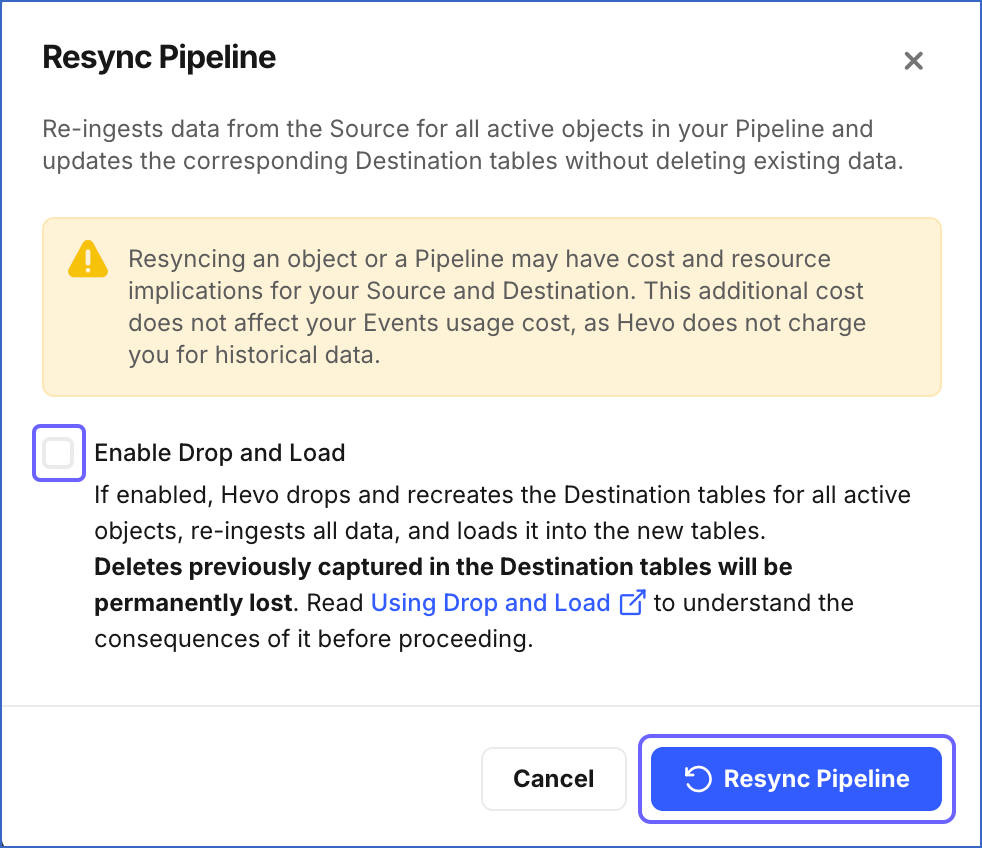
-
(Optional) Select the Enable Drop and Load check box if you want Hevo to re-create the Destination tables for all the active objects in your Pipeline during the resync operation.
-
Click Resync Pipeline to confirm the action.
-
After you click Resync Pipeline, Hevo performs the following actions on your Edge Pipeline:
-
Move the Pipeline to the Resyncing state.
-
Cancel any actively running jobs in the Pipeline.
-
Drop and re-create the resources in your Source system that Hevo uses while ingesting data.
-
Refresh the Source and Destination schemas.
-
Compare the refreshed schemas and evolve the schema of the Destination tables based on the detected changes.
-
Optionally, drop and re-create the Destination tables if the drop-and-load option is selected.
-
Start the historical data sync for all objects included in the Pipeline. After the historical data sync is successful, the incremental data sync is run on schedule as per the configured frequency.
-
Move the Pipeline to the Enabled state.
Note: If any of the tasks fail, the Pipeline moves to the Failed state. You can try enabling the Pipeline later, and if the issue persists, contact Hevo Support.