Pipeline Job History (Edge)
A Job represents a complete Pipeline run, encompassing both the stages of data replication: Ingestion and Loading. It processes an immutable set of tasks to replicate the data for the selected objects successfully to the Destination.
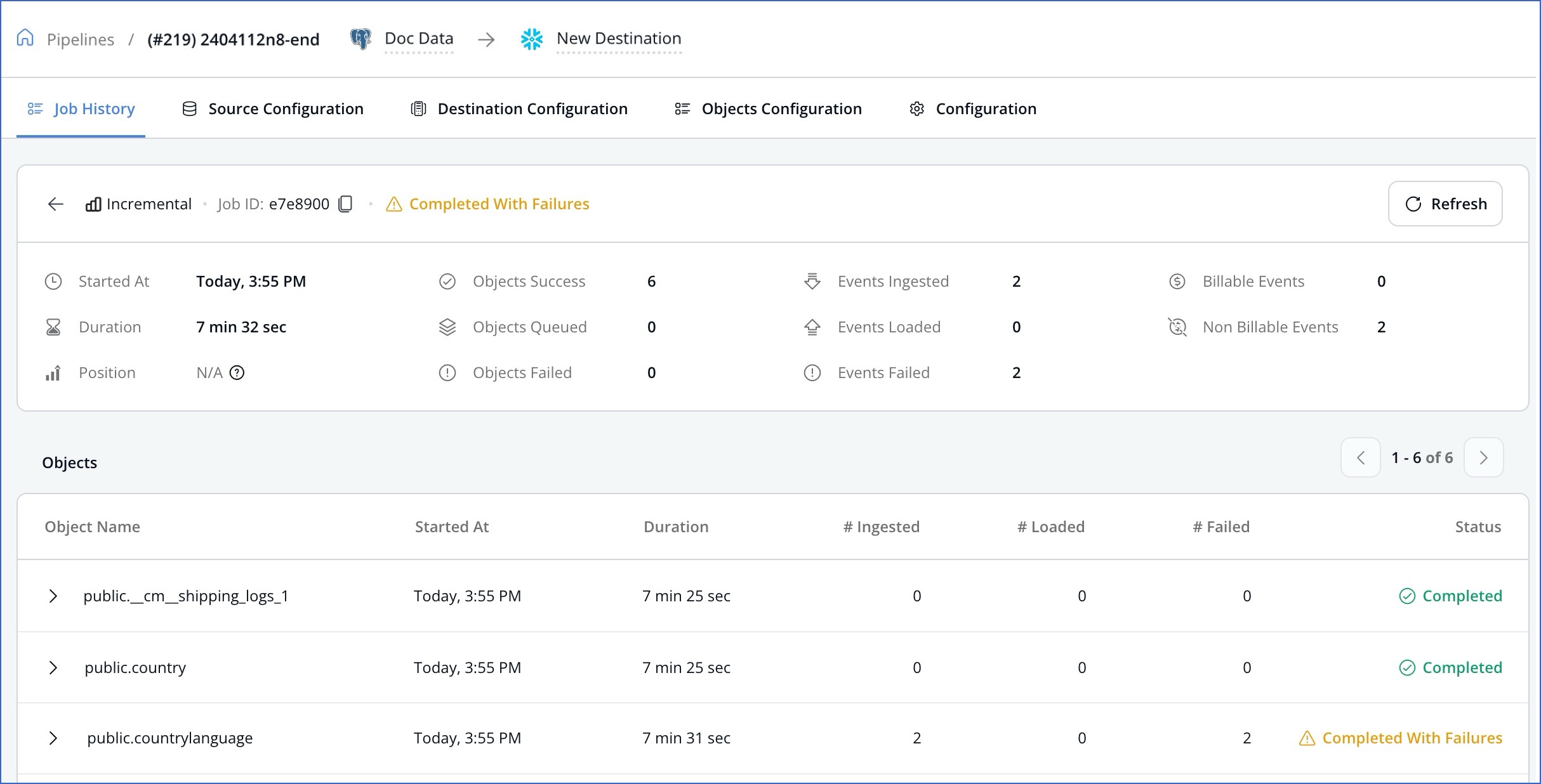
A job provides you with both a high-level and a granular view of the entire data movement lifecycle from the Source to the Destination along with any associated metadata. You can view the job details to know:
-
The data replication timeliness
-
The data volume correctness
-
The Events processed at either stage (ingest or load) in the job.
-
Errors logged in a job run.
These details can help you identify any data mismatches, latencies, and Event consumption spikes.
The following image shows a sample job details page.
A job is created once you configure your Pipeline, based on the type of data that is to be ingested. For example, historical or incremental jobs. Read Job Types for more information. Each job is assigned a Job ID and includes the batch of Source objects to be replicated. All objects in the batch carry the parent job’s ID. At times, a job may be created for an object that you restarted from the UI. Once such jobs are complete, the normal job schedule as per the defined sync frequency is resumed.
For the same Pipeline, no two jobs run concurrently. Therefore, if both historical and incremental data are to be loaded for the Source objects, the incremental job starts only upon completion of the historical load. Within a job run, ingestion replication of Events is done exactly once per object.
Note: We recommend that you define longer log retention periods for log-based Sources to reduce the risk of log expiry and loss of Events in case jobs run for very long durations.
Read through the pages in this section to know more about the job types, job processing modes, and the mechanisms for handling failed jobs and objects.
- Articles in this section