Pipeline Schema Management
Once you have configured the Pipeline, Hevo maps the Source schema to the Destination tables and columns. Read Schema Evolution to understand how Hevo handles changes in the Source and Destination schemas and applies them to evolve the Destination schema. As part of schema evolution, Hevo automatically does the following:
-
Compresses long names of Source objects and columns: Hevo creates meaningful, shorter names to adhere to the character limit set for the table and column names in the Destination.
-
Sanitizes table and column names: Hevo performs automatic name sanitization to ensure the objects follow the naming convention supported by the Destinations.
-
Evolves the Destination schema: Hevo modifies the Destination schema based on the respective Destination data types to accommodate any user-defined changes in the Destination schema.
Schema Evolution
Hevo stores the metadata of the Source schema in what is essentially a metastore. The metastore includes information such as the structure of tables, column data types, and other details required to understand and query the data. A similar metastore is created to store the metadata, namely the structure of tables and column data types, of the most recently known Destination schema. These metastores are designed to accommodate any user-defined changes in their respective schemas. Hevo generates a mapping during the data ingestion phase, encapsulating changes in the Source schema, combining them with the object configuration preferences, the selected Schema Evolution Policy, and the stored Destination schema. Hevo then applies this mapping during the data loading phase to evolve the schema of the Destination tables based on the respective Destination data types.
However, if applying the mapping results in an incompatible schema, the data loader does not load data into those objects and fails the batch. In this case, you can resync the Pipeline or object and trigger the Drop and Load action. At the Pipeline level, Hevo drops all the active objects in the Pipeline and re-creates them with the new schema. Similarly, at the object level, the entire object is dropped and re-created.
Using Drop and Load
You may trigger the drop and load action during a resync operation when Hevo cannot evolve the Destination schema or when recent schema changes result in an incompatible structure. The Drop and Load action can be triggered for all active objects in the Pipeline or for individual objects.
When this action is invoked during the resync operation, Hevo performs the following actions for each affected object in your Destination:
-
Creates a backup of the existing Destination table, if any, to prevent any potential data loss. The backup table is named using the convention <table_name>_backup_<unique_identifier>, where the unique identifier represents the batch that ran the load job.
-
Drops and recreates the Destination table using the evolved schema.
-
Reloads data ingested from the corresponding Source object into the newly created table.
Performing this action may result in the following:
-
Any records that were deleted at the Source but previously captured in the Destination tables will be permanently removed and cannot be recovered.
-
Triggering a full data reload may increase compute and storage usage on your Source and Destination.
Note: If the Drop and Load action is triggered for an object that loads data into a transient table in Snowflake, both the backup table and the new table are also created as transient.
Data Type Evolution
Hevo uses the metadata of the Source system to detect the column data types. It then transforms them using a widening hierarchy to Destination-specific equivalent data types. The column data types are safely evolved to broader or more flexible ones without data loss. Some such conversions are:
| Conversion Hierarchy | Effect |
|---|---|
| Integer → BigInteger → Float → String | Numeric values may be widened to prevent overflow or precision loss. |
| Date → Timestamp | Time granularity is added without affecting existing date values. |
| Boolean → Integer → String | Boolean values (TRUE/FALSE) can be evolved into integer values (1/0) and eventually into strings ("true"/"false"). |
This hierarchical approach of evolving data types:
-
Allows new data types to be introduced while ensuring the validity of existing data.
-
Reduces operational complexity by minimizing the schema changes.
-
Prevents data transformation errors by preserving data type compatibility across Destinations.
-
Ensures schema consistency through enhanced mapping accuracy.
Hevo has a standardized data system that defines unified internal data types, referred to as Hevo data types. These are typically a superset of the data types available at the Destination. The following image illustrates the data type hierarchy for Hevo data types:
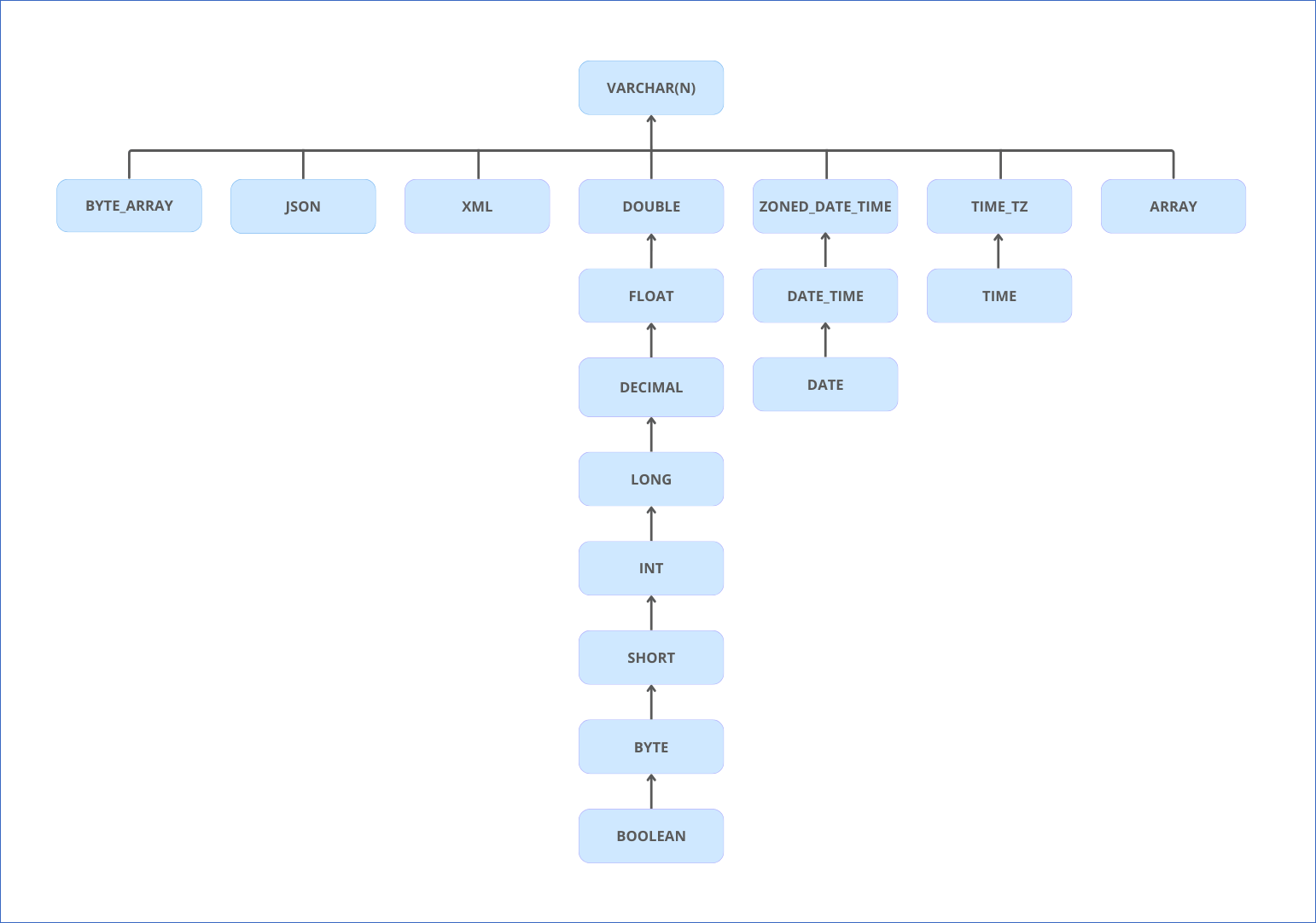
The table below provides an explanation of the Hevo data types:
| Hevo Data Types | Definition |
|---|---|
| BOOLEAN | Represents truth conditions, that is, True or False. |
| BYTE | Represents 8-bit signed integer values. |
| SHORT | Represents 16-bit signed integer values. |
| INT | Represents 32-bit signed integer values. |
| LONG | Represents 64-bit signed integer values. |
| FLOAT | Represents single-precision 32-bit IEEE 754 floating-point numbers. |
| DOUBLE | Represents double-precision 64-bit IEEE 754 floating-point number. |
| DECIMAL(p,s) | Represents decimal values with optional precision and scale measures. |
| VARCHAR(N) | Represents a string holding Unicode and ASCII characters with optional length N. |
| BYTE_ARRAY(N) | Represents an array of bytes used to store binary data with optional length N. |
| JSON | Represents key-value pairs as per standard JSON format. |
| XML | Represents an XML document in string format. |
| ARRAY | Represents a sequence of elements of the same Hevo data types. |
| DATE | Represents date values without timezone information. |
| TIME | Represents time values without timezone information. |
| TIME_TZ | Represents time values with timezone information. |
| DATE_TIME | Represents date and time values without timezone information. |
| ZONED_DATE_TIME | Represents date and time values with timezone information. |
Schema Evolution Policy
The Schema Evolution Policy defines how Hevo handles any changes that occur in the Source data after a Pipeline is created. These changes can include modifications to the Source columns, schemas, or tables. This policy ensures that data is replicated seamlessly between the Source and Destination, as per your requirements.
Note: If a Source schema is renamed, Hevo does not automatically map it to the Destination schema associated with the Pipeline.
Hevo follows a consistent naming convention for the schemas it creates across all Destinations. This convention helps you easily identify and locate the data entities created by Pipelines in your Destination. The schema name generated by Hevo cannot be modified after the Pipeline is created. If schemas are manually renamed in the Destination, it may lead to data inconsistencies because Hevo continues to create data entities using its predefined naming convention. If you need to load data into a different schema or use a different Destination prefix, you must create a new Pipeline with the required configuration.
You can choose from the following options:

-
Allow all changes: Hevo syncs any compatible changes in the Source schema post-Pipeline creation with the Destination as soon as they are detected. For example, if a table is added or deleted in the Source, Hevo evolves the Destination schema accordingly. When new tables are added, historical load is triggered first, followed by incremental.
-
Block all changes: Hevo does not sync any changes in the Source columns, schemas, and tables with the Destination.
-
Allow column-level changes only: Hevo syncs any compatible changes made to the column(s) of the selected Source object(s) with the Destination as soon as they are detected. For example, if a column is added or deleted in the Source object, Hevo evolves the Destination schema accordingly.
Note: If no data is present in the newly added columns or tables at the Source, Hevo does not automatically detect these changes. This is because Hevo reads the schema changes from the Source database logs, and they do not capture this information. You need to manually refresh the schema to view such tables and columns in the Object Configuration tab. Once the schema is refreshed, the newly added objects are auto-selected for data ingestion if your Schema Evolution Policy is set to Allow all changes. Similarly, in the case of Allow column-level changes only, the columns are auto-selected for data ingestion. In the case of Block all changes, you need to select the objects if you want to ingest data from them.
Depending on your selection, Hevo syncs the necessary changes with the Destination. The following table explains the Pipeline behavior corresponding to the various scenarios that may occur in the Source:
| Changes in the Source | Hevo Behavior |
|---|---|
| Column Added |
Allow all changes: Hevo starts syncing the new column as soon as it is detected and inserts null values for the existing rows. Block all changes: Hevo does not sync the new column with the Destination. However, the column will be visible on the Fields Selection page of the object and can be included for ingestion and loading. Allow column-level changes only: Hevo starts syncing the new column as soon as it is detected and inserts null values for the existing rows. |
| Schema Added |
Allow all changes: Hevo starts syncing the tables in the new schema as soon as they are detected. Block all changes: Hevo does not sync the new schema with the Destination. However, the tables in the new schema will be visible in the Object Configuration tab and can be included for ingestion and loading. Allow column-level changes only: Hevo does not sync the new schema with the Destination. However, the tables in the new schema will be visible in the Object Configuration tab and can be included for ingestion and loading. |
| Table Added |
Allow all changes: Hevo starts syncing the new table as soon as it is detected. Block all changes: Hevo does not sync the new table with the Destination. However, this table will be visible in the Object Configuration tab and can be included for ingestion and loading. Allow column-level changes only: Hevo does not sync the new table with the Destination. However, this table will be visible in the Object Configuration tab and can be included for ingestion and loading. |
| Column Renamed |
Allow all changes: Hevo creates the new (renamed) column in the Destination table, inserts null values for the existing rows, and starts loading data into that column from the next Pipeline run. For all future Pipeline runs, the older column is updated with null values. Block all changes: Hevo does not sync the renamed column with the Destination, and the existing column remains as is. Allow column-level changes only: Hevo creates the new (renamed) column in the Destination table, inserts null values for the existing rows, and starts loading data into that column from the next Pipeline run. For all future Pipeline runs, the older column is updated with null values. |
| Table Renamed |
Allow all changes: Hevo creates the new (renamed) table at the Destination and starts loading data to it from the next Pipeline run. The existing table in the Destination remains unchanged. Block all changes: Hevo does not sync the renamed table with the Destination. Also, the existing table in the Destination remains unchanged. Allow column-level changes only: Hevo does not sync the renamed table with the Destination. Also, the existing table in the Destination remains unchanged. |
| Column Deleted |
Allow all changes: Hevo populates the column in the Destination with null values from the next Pipeline run. Block all changes: The existing column in the Destination remains unchanged, and Hevo does not delete it. Allow column-level changes only: Hevo populates the column in the Destination with null values from the next Pipeline run. |
| Schema Deleted |
Allow all changes: The existing schema in the Destination remains unchanged, and Hevo does not delete it. Block all changes: The existing schema in the Destination remains unchanged, and Hevo does not delete it. Allow column-level changes only: The existing schema in the Destination remains unchanged, and Hevo does not delete it. |
| Table Deleted |
Allow all changes: The existing schema in the Destination remains unchanged, and Hevo does not delete it. Block all changes: The existing table in the Destination remains unchanged, and Hevo does not delete it. Allow column-level changes only: The existing table in the Destination remains unchanged, and Hevo does not delete it. |
| Column Reordered |
Allow all changes: Hevo does not make any changes to the column order in the Destination. Block all changes: Hevo does not make any changes to the column order in the Destination. Allow column-level changes only: The existing table in the Destination remains unchanged, and Hevo does not delete it. |
| Column Data Type Updated |
Allow all changes: Hevo updates the data type of the column in the Destination. Block all changes: Hevo updates the data type of the column in the Destination. Allow column-level changes only: Hevo updates the data type of the column in the Destination. Read Data Type Evolution to know how Hevo assigns and handles data types while replicating data. |