Supporting Partitioned Tables in BigQuery (Edge)
In BigQuery, large tables can be divided into smaller segments called partitions. By partitioning large tables, you can improve query performance and control costs, as the number of bytes read by the query is reduced.
In a partitioned table, BigQuery segregates the data into partitions based on the values in a specific column called the partition key or partition column.
BigQuery supports the following types of table partitioning:
-
Ingestion time-based: In this type, partitions are created based on when BigQuery receives the data.
-
Integer range-based: In this type, partitioning is done based on the ranges of values in the specified integer type column.
-
Time unit-based: In this type, tables are partitioned based on the values in a date, timestamp, or datetime type column.
For BigQuery Destinations in Edge, Hevo supports loading data into partitioned tables created using any of the types mentioned above. However, for a table partitioned by an integer range or a time unit, the partition key must be a single-column primary key for the corresponding Source object. For such tables, Hevo optimizes the data scanned by using the partition key in the MERGE and UPDATE queries run to load data. In the case of ingestion time-based partitioned tables, Hevo performs a full table scan to prevent data duplication.
To reduce the amount of data scanned and thereby the cost, Hevo includes a qualifying filter in the query. BigQuery prunes the partitions based on the filter, reading data from only those partitions that match the query filter and skipping the remaining ones.
Loading Data into Partitioned Tables
You can configure your Hevo Edge Pipeline to load data into a partitioned table. For this, perform the following steps:
-
Log in to your BigQuery console and select the dataset into which you want Hevo to create your BigQuery tables. You can use an existing dataset or add a new one.
Note: Hevo creates datasets using the Destination Prefix and your Source database or schema name. Hence, you must ensure that the selected dataset follows Hevo’s naming conventions. For example, mysql_bq_sakila, where mysql_bq is the Destination prefix and sakila the Source database.
-
In your dataset, create an empty table partitioned using any one of the supported partitioning types. Ensure that the table is named exactly as your Source table. For example, payment.
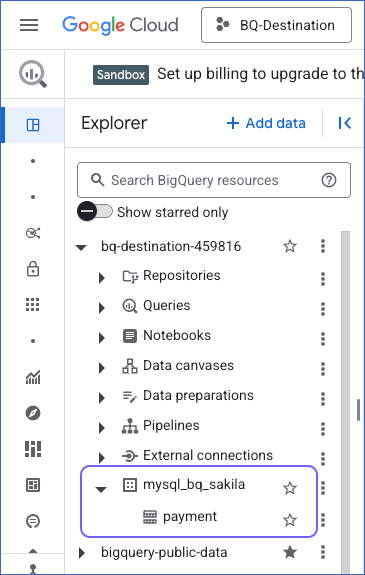
Note: Except for ingestion time-based partitioning, you must use a single-column primary key from your Source table as the partition key. The primary key must be defined on an integer or a time-unit type Source column.
-
Log in to your Hevo account and in the Edge user interface, do the following:
-
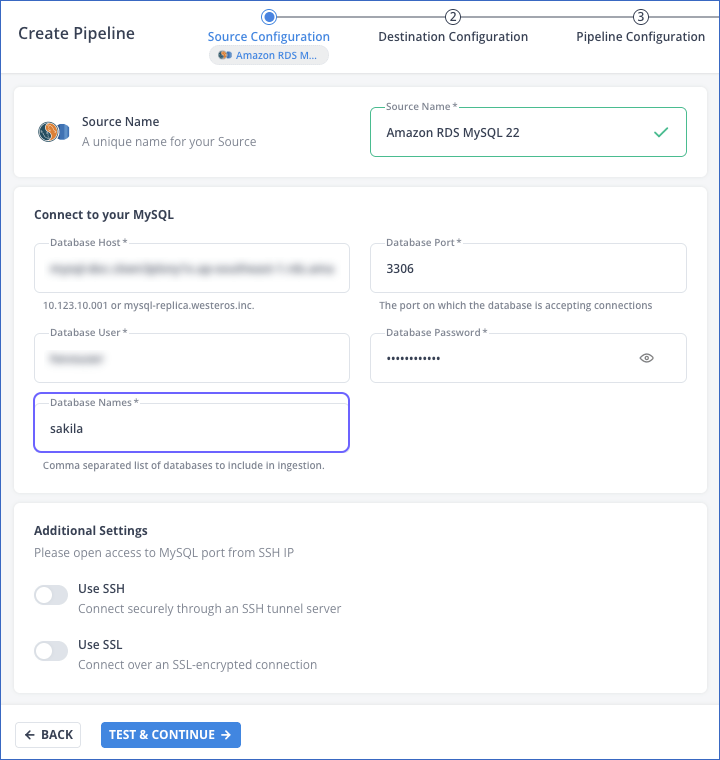
Configure the Source and the database from where you want to ingest data. For example, the sakila database in Amazon RDS MySQL.
-
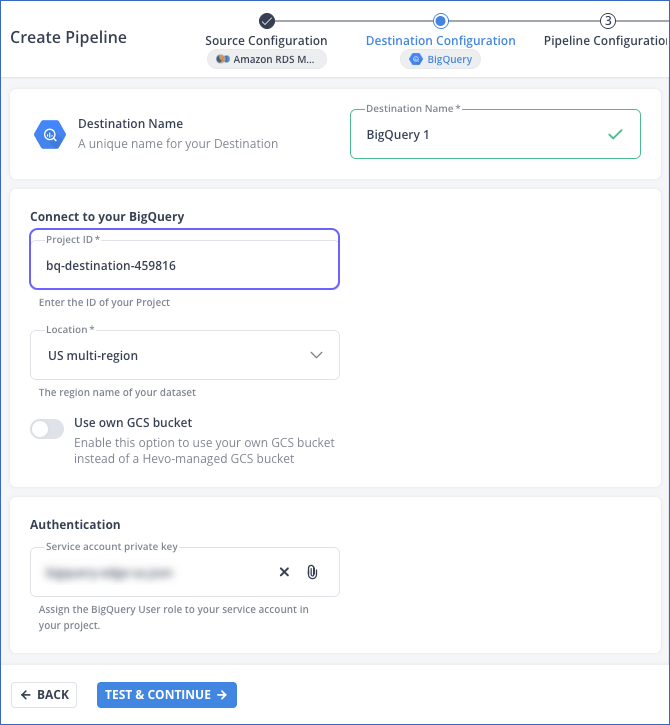
Configure your BigQuery Destination with a service account that has access to the dataset containing the partitioned table created above.
-
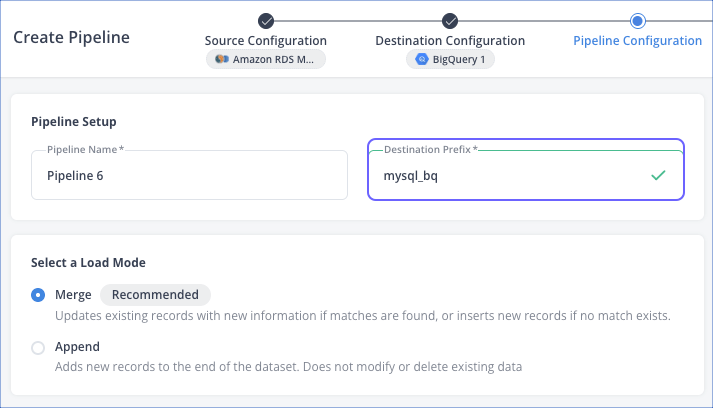
In the Pipeline Settings, ensure that the combination of the Destination Prefix and the name of the database or schema configured in your Source matches the name of your BigQuery dataset. For example, if your dataset is mysql_bq_sakila, specify the Destination Prefix as mysql_bq.
-
In the Object Configuration screen, select the Source object whose data is to be loaded into the partitioned table. For example, the payment object.
-
-
Review the configuration displayed in the Summary screen and save your Pipeline to start data replication.
Once the load job is complete, you can verify from the BigQuery console that data is loaded into your partitioned table.