Structure of Data in the Amazon Redshift Data Warehouse
Amazon Redshift is a data warehouse that is specifically designed for online analytic processing (OLAP) and business intelligence (BI) applications which require complex queries against large datasets.
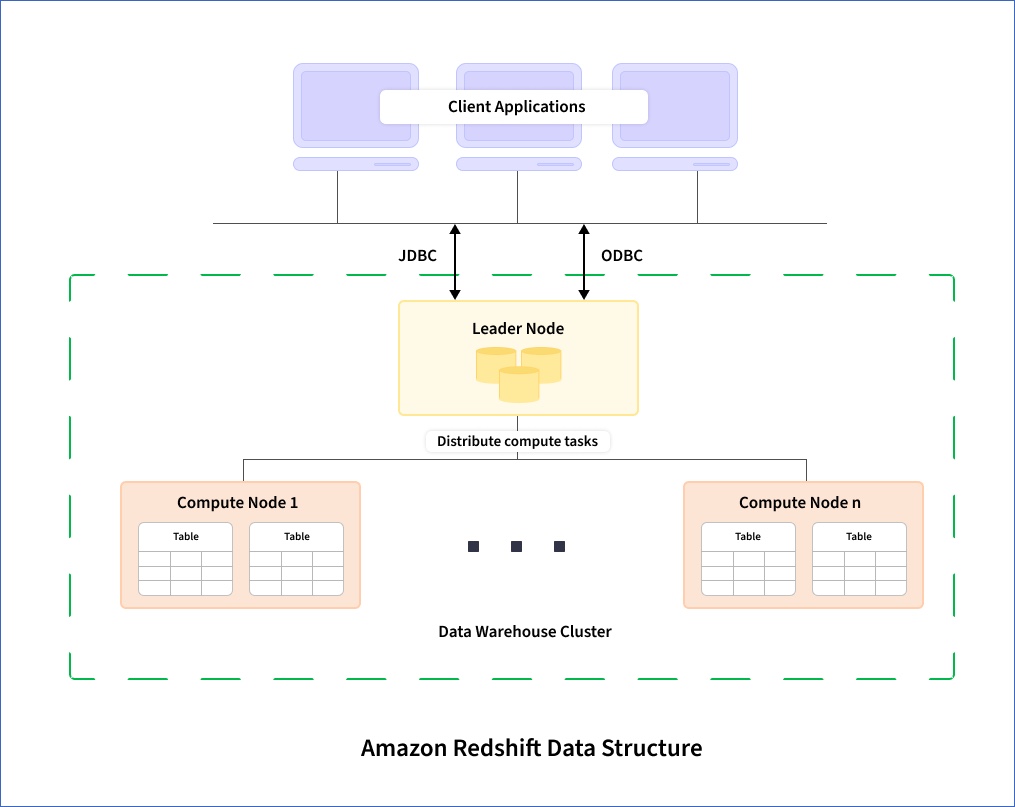
Amazon Redshift Data Architecture
The core infrastructure component of a Redshift data warehouse is a cluster. A cluster is made up of nodes, or computing resources. One of the nodes acts as a Leader node and the others as Compute nodes. The leader node manages communication with clients, creates execution plans for queries, and assigns tasks to compute nodes. The data of each database is stored on the compute nodes. Each compute node has its own CPU, memory, and storage disk. The multiple nodes allow Redshift to massively parallel-process data. While loading your data, Hevo communicates with the cluster’s leader node, which in turn coordinates the data replication query execution with the compute nodes.
As your requirements for storage and performance change, you can scale your Amazon Redshift cluster by adding more nodes, updating existing nodes, or both. Read Overview of managing clusters in Amazon Redshift.
Redshift Data Structure
A Redshift cluster may contain one or more databases. A database further contains tables, views, and procedures. Each database may have one or more schemas, and you can select the schema while creating a table. In Redshift, the default schema is public. When you create a Pipeline with a Redshift Destination in Hevo, you are required to select the schema along with the database. The data fetched from the Source application is loaded to the tables of the specified database and schema.
Amazon imposes certain restrictions on naming the clusters and databases. Read Naming constraints.
A parameter group is associated with each cluster that you create. It includes a set of parameters that apply to all the databases within the cluster and define the database settings. Read Amazon Redshift parameter groups.
Data Storage
Within the database tables, Redshift supports column-based storage of data. This means that unlike other SQL databases, one row of data is not stored together. Instead, the storage is based on columns as Redshift is a columnar database. This helps to optimize the performance of the data ingestion queries as columnar storage significantly reduces the number of I/O requests to be made for accessing the data. Read Columnar storage to know more.
For example, let us consider the following set of data:

In a row-based database, the data would be written to the database table one complete row at a time, as follows:

In a column-based database, such as Redshift, each row in the database table would hold the data of one column, as follows:

Columnar data offers more optimal storage due to better compression, as compression works better on similar data. Columnar storage also makes Redshift a good choice for a Destination when you have to aggregate lot of data from your Source(s), or for analytical processing, as analytical apps often aggregate lot of data from multiple columns but may not require searching an entire table.
Sort Keys and Distribution Keys
Sort keys and distribution keys decide how data is stored and indexed across all Redshift nodes. Therefore, you need to properly set them while creating the tables, for optimal performance.
Sort keys determine the order in which rows are stored in a table. Query performance is improved when the sort keys are properly used as fewer chunks of data need to be read and the majority are filtered out.
When your Hevo Pipeline loads data to the Redshift table, it is sorted as per the sort keys defined for it. The sorting is done in the order of listing of the sort keys in the table, and this order cannot be changed for an existing table. Read How can I change sort keys and their order in a Redshift Destination table? to know more.
Similarly, when you create a table, you can optionally specify (only) one column as the distribution key. When data is loaded to the table, the rows are distributed within the node according to the distribution key that is defined for a table. A well chosen distribution key minimizes the movement of data from node to node, thereby facilitating parallel processing for loading data and running queries efficiently. For information about choosing a distribution key, see Choose the best distribution style.
There can be only one distribution key for a table and that can not be changed later on, which means you must think carefully and anticipate future workloads before deciding on your distribution key.