Data Ingestion
The process of accessing and fetching the data residing in your Source application or database is called data ingestion. Many SaaS Sources provide their own APIs for this purpose.
Hevo ingests the data in one of the following ways:
-
Pull-based ingestion: In pull-based ingestion, Hevo’s ingestion task pulls data from your configured Source at a regular interval. This regular interval is termed the ingestion frequency. Hevo fetches data from most SaaS Sources and database Sources configured with the Table or Custom SQL ingestion mode using this technique.
-
Push-based ingestion: In push-based ingestion, Hevo acts as a receiver and it is the responsibility of the Source to send or post data. Hevo ingests data from webhook Sources using this method.
Types of Data
The data that the Hevo Pipeline replicates can be classified into three types:
-
Incremental: This includes any new data that is created or existing data that is modified after the Pipeline is created. This data is counted in your Events usage and is billed.
-
Historical: This is the data already present in your Source when you create the Pipeline. The Events loaded as historical data are not billed.
-
Refresher: For ad-based and analytics Sources, Hevo does a regular data refresh to ensure there is no data loss and to capture attribution-related updates. These Events are not billed.
Read Types of Data Synchronization to know about each type of data.
Ingestion Frequency
Your Pipeline schedule determines how frequently Hevo ingests the data from the Source. This is also called the ingestion frequency or Pipeline frequency. Each Source has a minimum, maximum, and default ingestion frequency. For most Sources, you can change this to a value based on the frequency range available for the Source.
Hevo defers the ingestion briefly in case any limits imposed by the Source APIs are being exceeded, for example, if the API rate limit is exceeded for a SaaS Source. The ingestion resumes as per the configured schedule or once the deferment period ends, based on whichever occurs first. Refer to the Source Considerations section in the respective Source document to know the applicable limits. For example, the Source Considerations section in the Pendo Source document describes the number of calls that can be made per second to any API endpoint.
Hevo also provides you the option to prioritize Pipelines, if needed.
Read the respective Source configuration document in this site for the possible ingestion frequencies.
Re-ingestion of Data
Re-ingestion of data may be the result of a manual action by you to restart the historical load for an object or a Source limitation. The former can be done using the Restart Object action. Historical data is always loaded for free. If an integration is configured to load the historical data for a fixed period, say the last 30 days, then the historical sync duration is calculated from the time of the restart action.

Sample re-ingestion scenarios:
-
The user has applied some pre-load Transformations or has changed the schema mapping, and wants to apply the updated logic to the entire data.
-
The log file of a database Source has expired and the log-based Pipeline is unable to read the data. In such a case, you can restart the historical load for the configured historical sync duration or change the position to load the historical data from a particular record onwards. You can do this for some or all the objects you selected for ingestion.
-
For Sources such as Google Sheets, the entire data is re-ingested each time there is a change to the data in the Source, as Google Sheets does not provide a worksheet or row-level timestamp to identify the changes.
Data Ingestion Status
Once you have created the Pipeline, you can refer to the Pipeline Activity section of the Pipeline Overview page to see if the ingestion of data is successfully initiated.
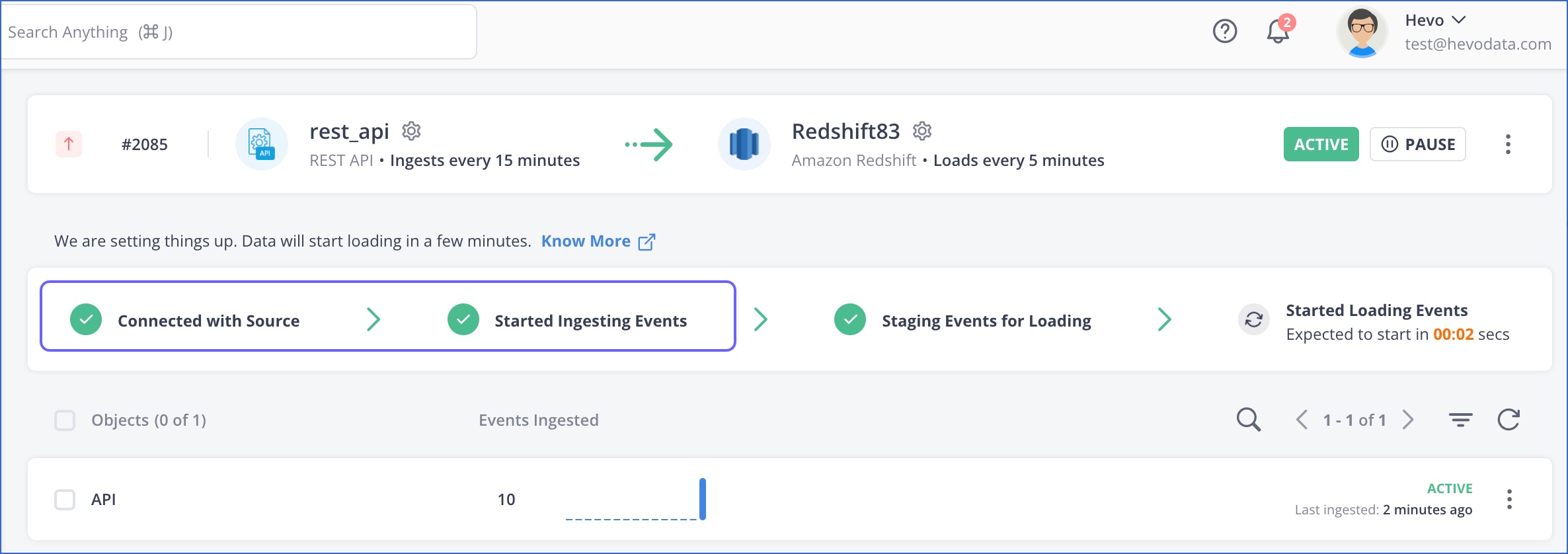
You can also view the ingestion status for each object to know its progress and success. In case Events are not found in the Source system at any time, Hevo may defer the ingestion for a short while. Read Data Ingestion Statuses.

Data Ingestion Thresholds
After creating your Pipeline, you can set a daily data ingestion threshold to limit the number of Events ingested and loaded for that Pipeline. This ensures that your Pipeline(s) do not consume any extra Events than the defined threshold and the Events quota is not exhausted.

You can also select the option to pause the Pipeline if the number of Events ingested and loaded by your Pipeline exceeds the threshold. Hevo sends you an alert on the UI, email, and Slack or any third-party incident management tool (if enabled), after which you can take the desired action. Read Data Spike Alerts for steps to set the threshold and enable the alert.
Note: The option to pause the Pipeline after exceeding the threshold is not available for log-based Pipelines. This is because pausing the Pipelines may cause the logs to expire, which might lead to loss of data.
Included and Skipped Objects
At any time, you can include objects you had skipped earlier or vice versa. Read Managing Objects in Pipelines. The object is queued for ingestion as soon as you include it.
In case of webhook Pipelines, if you want to skip some objects or fields, you can do this using Transformations or the Schema Mapper page.
- Articles in this section
- Types of Data Synchronization
- Ingestion Modes and Query Modes for Database Sources
- Ingestion and Loading Frequency
- Data Ingestion Statuses
- Deferred Data Ingestion
- Handling of Primary Keys
- Handling of Updates
- Handling of Deletes
- Hevo-generated Metadata
- Best Practices to Avoid Reaching Source API Rate Limits